Automatically Redact Faces with PSPDFKit for iOS

A PDF document can contain several kinds of sensitive information that we may want to remove, including pictures of someone’s face. In this blog post, I’ll describe how you can automatically perform facial redaction in a PDF using both PSPDFKit for iOS and Core Image, an iOS framework.
Redacting Images from a PDF
In a previous blog post, I introduced the concept of redacting a PDF to remove sensitive information from it. A common use case for redaction is redacting text, but you can also redact images. One possible application of image redaction is the removal of headshots from résumés. While in some countries, résumés include a headshot, in others, it’s customary that résumés do not include any photograph, so as to avoid potential unconscious bias. For this reason, an HR department may want to remove photographs from résumés received in PDF form.
Redacting images with PSPDFKit is as easy as redacting text: First, you add a redaction annotation to the document on top of the image content you want to remove. Next, you apply the redaction annotation to actually remove the content under it — for example, by saving the document with the applyRedactions save option. You can get detailed information about this in our developer guides.
This process is simple and lets you redact images from PDFs easily. However, we could automate the process even more. The first step, adding a redaction annotation on top of the image content you want to remove, requires that a human actually determines which parts of the PDF contain an image and selects them with the mouse or manually calculates their coordinates. Both ways are not very efficient when you need to redact hundreds or maybe thousands of images from a PDF, like in the above example. Would it be possible to make the computer select the sensitive images automatically?
The answer is that, for some kind of images (like faces) we can use frameworks that implement a special kind of artificial intelligence (AI) algorithms to redact them. I’ll demonstrate this in the next section.
Using AI Algorithms to Automatically Select Images to Redact
AI has researched how to identify things in images for a long time. There’s a specific subfield in AI, image analysis, the focus of which is the research of algorithms that identify meaningful information from images.
Because of the broad applicability of image recognition algorithms, popular mobile frameworks like Android or iOS already include implementations of many of them. One of the best examples of this is Core Image, an iOS framework, which provides detection for faces or barcodes by means of the CIDetector class. The next section describes how you can use PSPDFKit and Core Image to automatically detect and remove faces from PDF files.
How to Redact Faces with PSPDFKit and Core Image
Here’s how you can redact faces using PSPDFKit and Core Image. First, create a CIDetector instance, which is the face detector:
let faceDetector = CIDetector(ofType: CIDetectorTypeFace, context: nil, options: [CIDetectorAccuracy: CIDetectorAccuracyHigh])!
Next, you need to render every PDF page and use the face detector to detect faces on them. Then, place a redaction annotation on top of each detected face. In code:
var documentRedactionAnnotations: [RedactionAnnotation] = [] for pageIndex in 0..<document.pageCount { // Render this page. For efficiency, we can work with a scaled page render and still get good results. let scaleFactor: CGFloat = 1 / 3.0 let pageSize = document.pageInfoForPage(at: pageIndex)!.size let scaledPageSize = CGSize(width: pageSize.width * scaleFactor, height: pageSize.height * scaleFactor) let renderedPage = try! document.imageForPage(at: pageIndex, size: scaledPageSize, clippedTo: .zero, annotations: nil, options: nil) // Detect faces on the rendered page. let ciImage = CIImage(cgImage: renderedPage.cgImage!) let transform = CGAffineTransform(scaleX: 1 / (scaleFactor * renderedPage.scale), y: 1 / (scaleFactor * renderedPage.scale)) let faces = faceDetector.features(in: ciImage, options: nil) // Place a redaction annotation on top of each detected face. let redactionAnnotations = faces.map { face -> RedactionAnnotation in let faceBounds = face.bounds.applying(transform) let redaction = RedactionAnnotation() redaction.boundingBox = faceBounds redaction.rects = [faceBounds] redaction.color = .orange redaction.fillColor = .black redaction.outlineColor = .green redaction.pageIndex = pageIndex return redaction } documentRedactionAnnotations.append(contentsOf: redactionAnnotations) }
The above code works as follows: The first line creates an array of redaction annotations. Then, a for loop goes through every page in the document and renders it by calling the imageForPage method of the PSPDFDocument class. Note that we don’t usually need to render at the original page size to still get good detection results, so we can scale the page down before rendering it. We found that rendering a page at one third of its original size is a good tradeoff between accuracy and performance, but feel free to experiment with different scaling factors for your document.
The next step involves creating an instance of a CIImage and calculating an affine transform that will convert between the UIKit/PSPDFKit coordinate system (where the origin is at the top-left corner of the screen), and the CIImage coordinate system (where the origin is at the bottom-left corner of the screen). Faces are detected by calling the features method of the face detector. Once we have a list of faces in the faces variable, we can create a redaction annotation for each one and append these annotations to the documentRedactionAnnotations variable.
Once we have a list of redaction annotations, we need to add them to the PDF document so that they can be applied later:
document.add(annotations: documentRedactionAnnotations)
The last step is to apply the redaction annotations to actually remove the image information from the PDF:
let processorConfiguration = Processor.Configuration(document: document)! processorConfiguration.applyRedactions() let redactedDocumentURL = URL(fileURLWithPath: NSTemporaryDirectory()).appendingPathComponent("redacted.pdf") let processor = Processor(configuration: processorConfiguration, securityOptions: nil) try! processor.write(toFileURL: redactedDocumentURL)
The final result will be in a redacted.pdf file created on the iOS temporary directory. The image below shows how redacted.pdf looks.
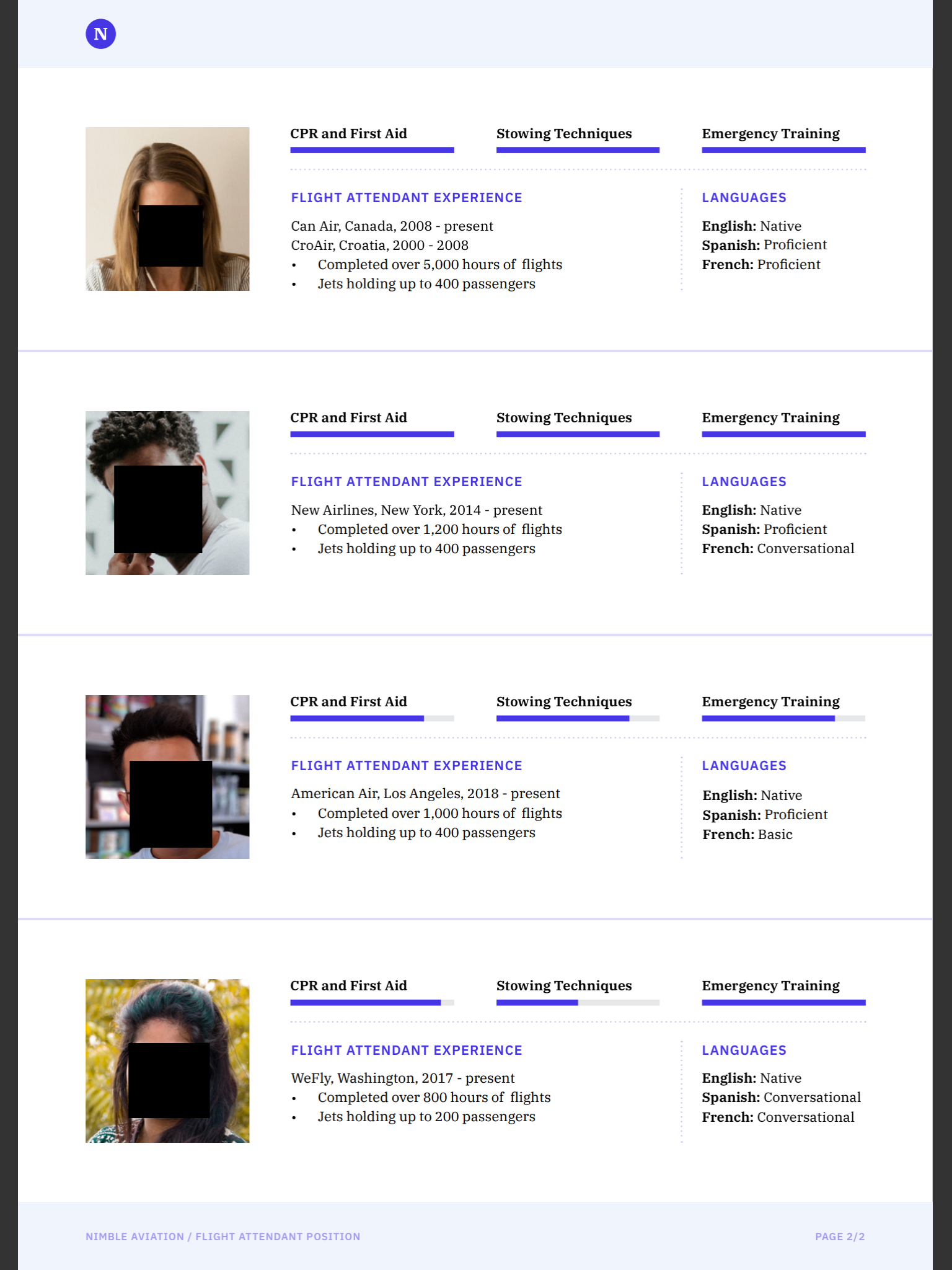
As of PSPDFKit for iOS 9.3.0, you can see this code in action in the Face Redaction Catalog example.
Conclusion
This article has described one way of how image redaction and face detection can remove sensitive images from a PDF without any human intervention. This kind of “data-driven” redaction is very powerful, and we already described how to use it for text and our PSPDFKit for Java library in a previous blog post.
Using the extensive redaction capabilities of PSPDFKit and the face detection support from Core Image on iOS, we can achieve fairly good results with a small amount of code. We are happy to help you explore ways to permanently remove sensitive information from your documents. Feel free to contact us with your use case.

Daniel is part of the Core Team at PSPDFKit and has worked on multiple topics, ranging from cryptography and text systems, to file format support and JavaScript engines. Outside of work, he likes spending time with his family, football, reading books, and watching films.