Data-Driven Redaction in Java
When distributing documents, we are often concerned with not leaking sensitive information. For example, it would not be wise to leak account numbers and passwords of your clients. As such, we need a solution to remove data from a document before we send it out. To identify the data we want to remove, we need some way of reading from a source of information that holds the sensitive information. Only when we have this information can we remove the data from the document, and this removal process of content is called redaction.
Redaction in PDFs
When working with a PDF, you are not only dealing with a rendered image; you are also dealing with a complicated language describing the contents of a document, often with a historical changeset of the data if the document has been saved using incremental saving.
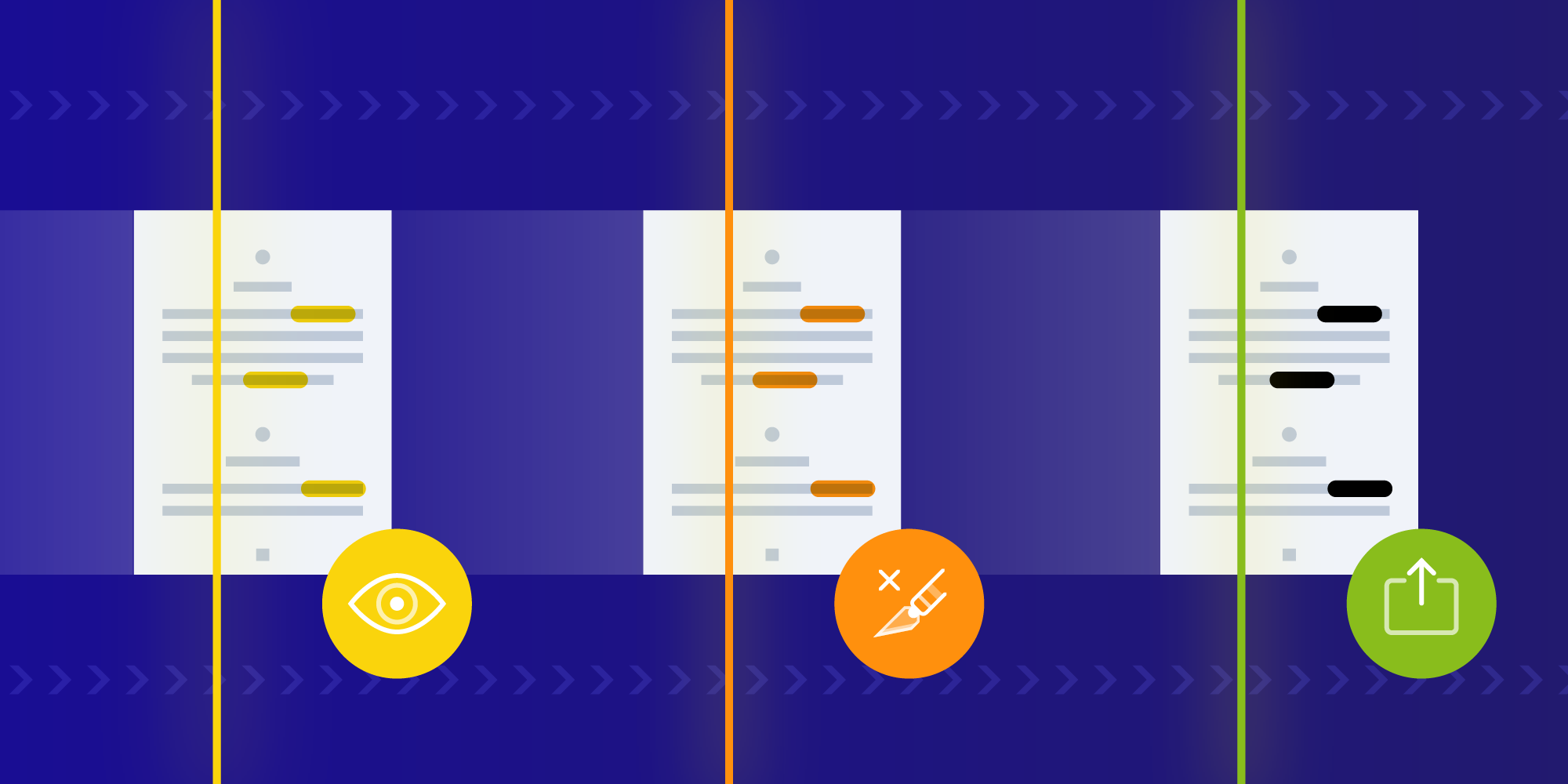
Therefore, in the process of redacting a document, it’s imperative to not only obscure the rendered image, but also to remove all references to the data in the contents of the document. To do this, there are two distinct steps that are required:
-
Marking areas for redaction — Adding redaction annotations as described in the PDF specification.
-
Removing the content — Irreversibly removing the page content within the region of the redaction annotations.
How Can We Redact in Java?
In PSPDFKit 1.1 for Java, we added an all-new RedactionProcessor API, which is capable of redacting for a variety of use cases — from removing simple strings to removing complex data with preset search algorithms. It allows for batch processing of multiple documents, limiting redactions to specific pages, and changing the color of the box that is placed over the redacted content.
Reading Data from a CSV File
In our simple example, we’re going to construct a redaction template from a CSV file, so first let’s set up a simple function to read from a CSV file.
Please be aware that the following method is not a complete implementation for a CSV parser, but rather a subset to prove the example. If you’re wanting a more complete parser, I’d suggest looking into OpenCSV, or the Apache Commons CSV library:
@NotNull public List<String> readCsvValues(@NotNull final File csvFile) throws IOException { final List<String> readCsvValues = new ArrayList<>(); final String cvsSplitBy = ","; BufferedReader bufferedReader = null; String line; try { bufferedReader = new BufferedReader(new FileReader(csvFile)); while ((line = bufferedReader.readLine()) != null) { readCsvValues.addAll(Arrays.asList(line.split(cvsSplitBy))); } } finally { if (bufferedReader != null) { try { bufferedReader.close(); } catch (IOException e) { e.printStackTrace(); } } } return readCsvValues; }
Here we are going to receive all the values read from the CSV file in a List of strings that’s ready for us to work with.
I’ll be using the following fake data to drive the redactions:
John,Smith,666-66-6666,123 456-7890,no_reply@example.com,123 Your Street,Your City,ST,12345
Set Up the Redaction Template
Now that we have the data and a CSV reader, we need to populate the RedactionProcessor API with redaction instructions (i.e. redaction templates). To do this, we’re going to use RedactionRegEx and populate the regex pattern with the literal string to search for:
final List<String> redactionData = readCsvValues(DocumentHelper.getAssetCopy("personal-data.csv")); final RedactionProcessor processor = RedactionProcessor.create(); // Populate the redaction templates. for (String redactionString : redactionData) { processor.addRedactionTemplates(new RedactionRegEx.Builder(redactionString).build()); }
Feed the Template into the Redaction Processor and Redact
We have a template of the data we want to redact, so now it’s time to let the API work its magic:
// Based on the templates created from the CSV file, redact the data and save the document.
processor.redact(pdfDocument);That’s it! Whichever document is referenced by pdfDocument has now been redacted with the data given by the CSV file and saved. John will no longer exist in the document, nor will his phone number, email address, or any other information referenced in the CSV file.
To take the example further, we could apply the redaction template to multiple documents — possibly documents all relating to “John Smith.” We would be feeding the personal data in along with all the documents held on the customer, safe in the knowledge that their data will be removed:
for (File fileToRedact : filesToRedact) { final PdfDocument document = PdfDocument.open(new FileDataProvider(fileToRedact)); processor.redact(document); }
Verifying the Removal of Data
But what if we want to be extremely certain that the data being removed is correct? Or that there aren’t instances of personal data still buried in the document? Well, rather than redacting the data straight away, we can just “stage” the redactions. Staging is the process of adding the redaction annotations but not applying the redactions:
processor.identifyAndAddRedactionAnnotations(pdfDocument); // Save the annotations back to the document. pdfDocument.save(new DocumentSaveOptions.Builder().build());
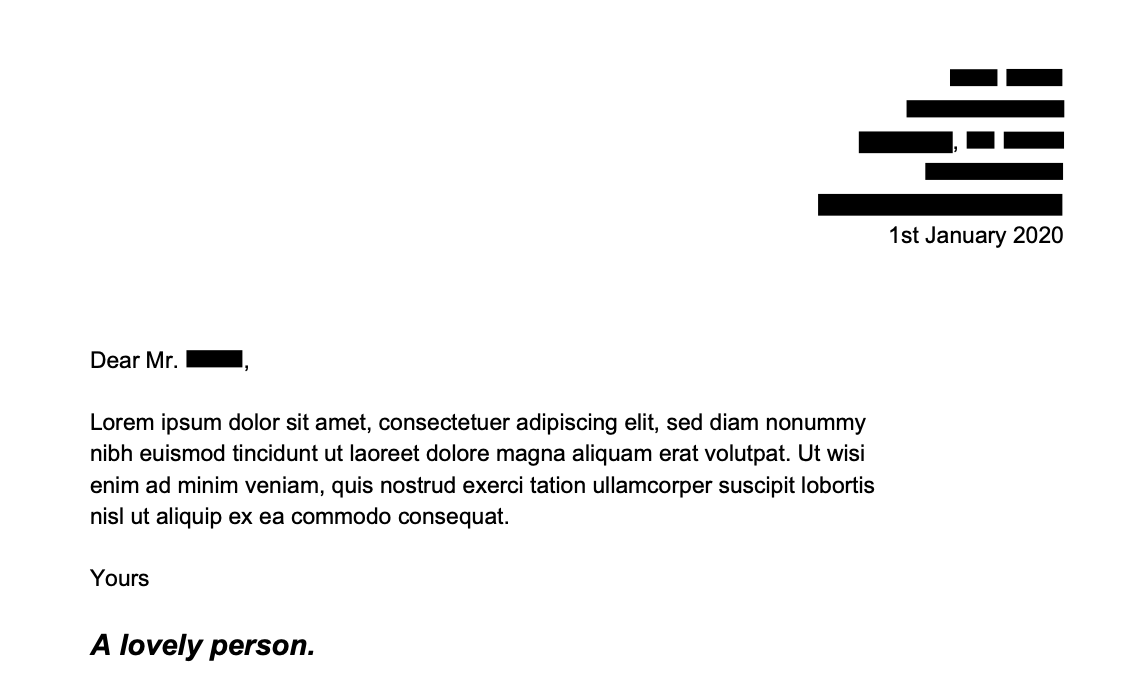
The saved document will contain content staged for redaction outlined in a red box, denoting that the content is staged to be removed. It could go through a human review or any other type of post processing before the redactions are then applied:
// Rewrite the document and redact the staged content. pdfDocument.save(new DocumentSaveOptions.Builder().applyRedactionAnnotations(true).build());
Now if you open the saved document, you will find black boxes covering all the sensitive information. And if you try to search for that redacted sensitive information, there will be no results found.
Conclusion
In this blog post, we’ve seen that it’s completely possible to take data from an external source and redact all matches of this data in one or more documents. This is an absolutely essential practice when working with sensitive information of clients or customers.
If you’re still interested in learning more about redaction and the PSPDFKit for Java SDK, I’d encourage you to head over and grab the trial. In there, you’ll also find a Catalog example with the full source code for the example seen in this blog post. You’ll find the example class under the name CsvDrivenRedaction.

When Nick started tinkering with guitar effects pedals, he didn’t realize it’d take him all the way to a career in software. He has worked on products that communicate with space, blast Metallica to packed stadiums, and enable millions to use documents through PSPDFKit, but in his personal life, he enjoys the simplicity of running in the mountains.