Java PDF Library A Reliable PDF Processing Library for Java
A powerful solution for batch processing, manipulating, and editing PDF documents.
A powerful solution for batch processing, manipulating, and editing PDF documents.

Search for personally identifiable information (text and images) and redact it automatically or stage it for redaction at a later point. You can use out-of-the-box presets or create custom search patterns using regular expressions. Frequently used in e-discovery, e-disclosure, legal, financial, healthcare, and government applications.
Securely and irrecoverably remove PDF text and images.
Ensure compliance with GDPR, HIPAA, and other privacy laws.
Rapidly process redactions across large batches of PDFs.


Access powerful low-level controls for merging PDFs, adding or deleting pages, appending cover sheets, and rotating pages. Assemble multiple documents into a single unified PDF for easier distribution and recordkeeping. Ensure document uniformity across all business processes.
Combine separate PDFs into one unified document.
Change page orientation to correct for landscape layouts.
Insert and delete specific pages, add custom cover sheets, and more.
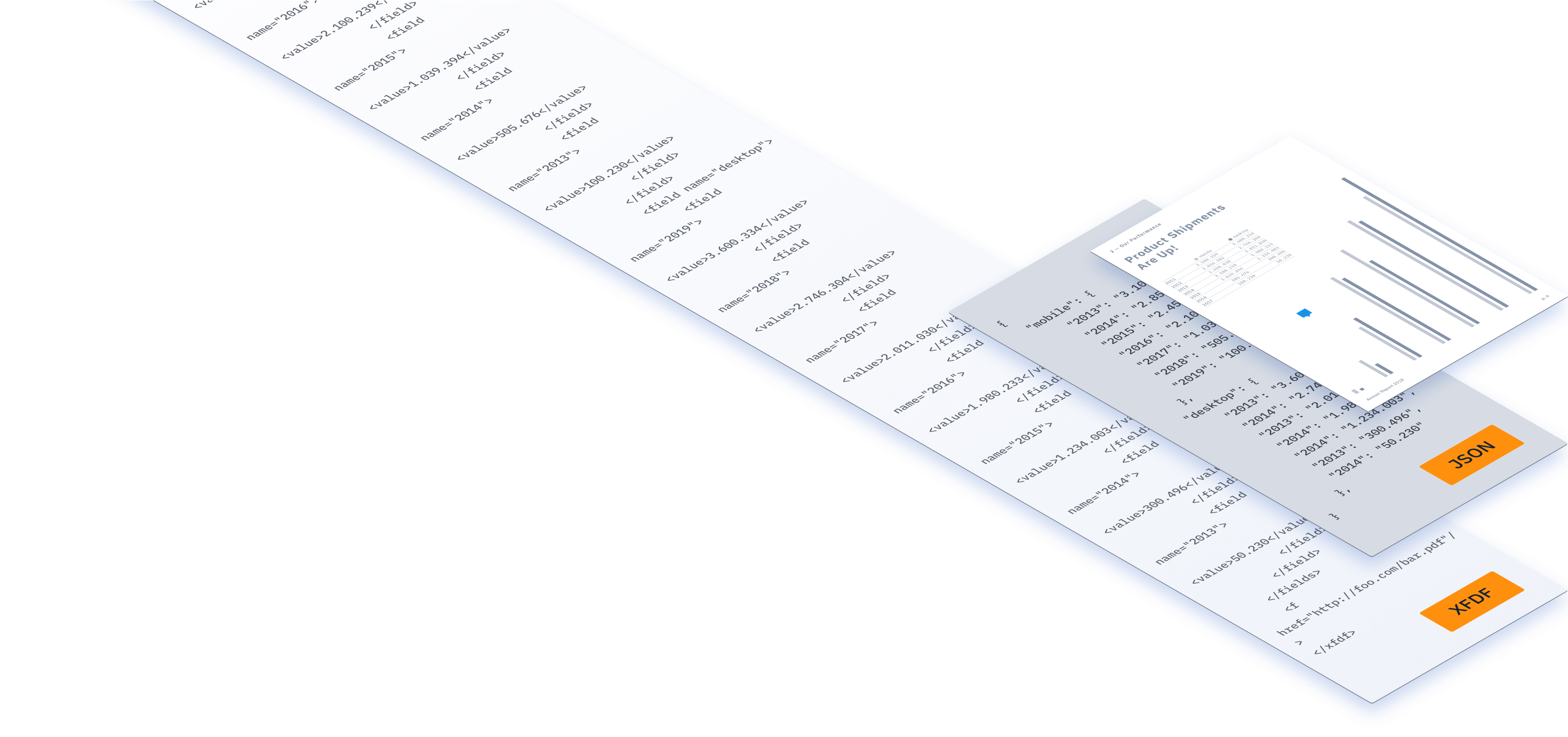
Extract annotation data from large volumes of PDF documents for exporting to a database. Optimize for speed and network traffic by transmitting only the user’s edited changes via XFDF or Instant JSON.
Use our proprietary Instant JSON format or XFDF to import and export large amounts of annotation data.
Permanently apply annotations by batch-flattening all changes to prevent further revision.
Extract user data from PDF form fields in XFDF.

Access the same powerful rasterizing engine that annually processes billions of documents for our customers worldwide. Easily integrate accurate document and page rendering into your existing workflows. Render large batches of PDFs to commonly used image file types.
Render PDF documents to be saved in your preferred image format.
Rapidly convert PDF documents or individual pages to high-fidelity bitmaps of any size.
Ensure precise file structure retention, with text layout and tables appearing exactly as shown in the original PDF.
Our Forms component enables you to programmatically read and write form values. Simply build a model of your data and call a single API to fill out forms.
Simplify the form filling workflow.
Automate data entry into your database.
Extract data from form fields in a document.

Our OCR processor quickly enhances raster and vector PDFs to give you interactable text, unlocking the full suite of PDF tools available.
Improved Accessibility
Accelerated Text Extraction
Process Automation

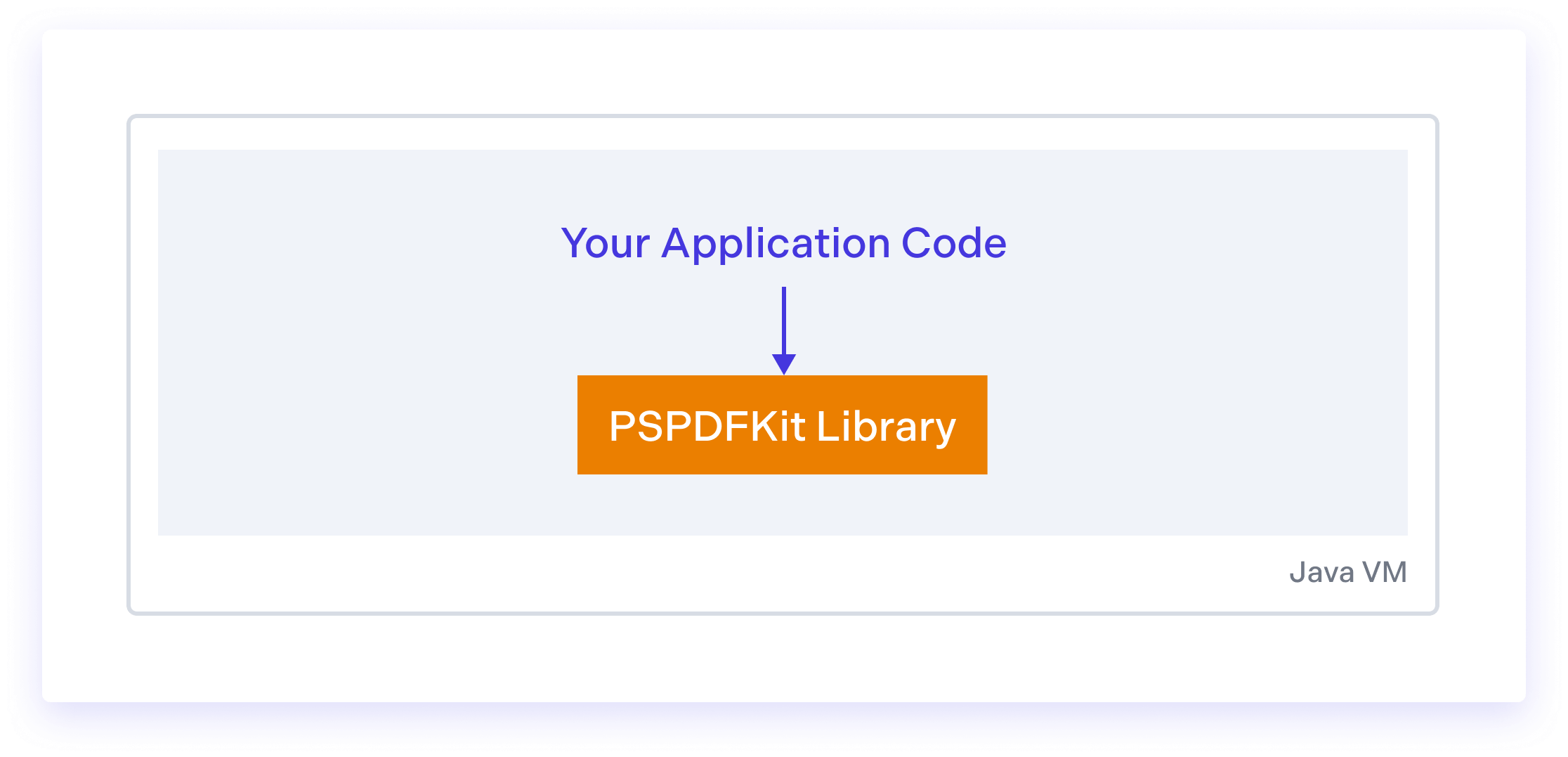
PSPDFKit can be integrated with just a few lines of code, and it comes with a rich API, which allows for complete customization.
PSPDFKit Processor, Libraries for Java and .NET, and Server were created with different use cases in mind. Check out the short comparison below to see which one is for you.


