PDF Processor A Powerful and Scalable PDF Processor
A powerful solution for batch processing, manipulating, and editing PDF documents. Easy to deploy, easy to use.
A powerful solution for batch processing, manipulating, and editing PDF documents. Easy to deploy, easy to use.
Built with a single goal in mind: to make it easier for you to integrate PSPDFKit into your document workflows.
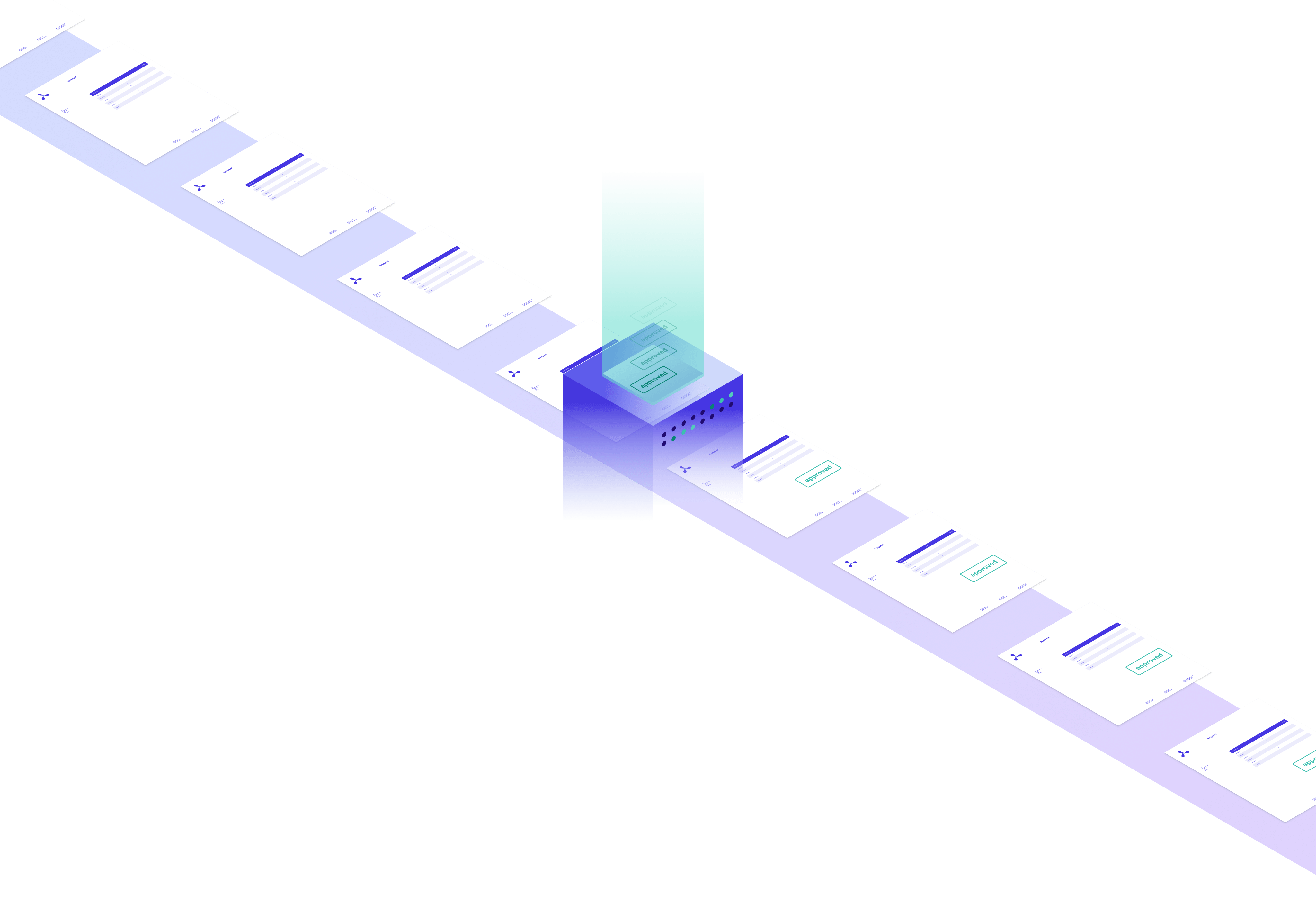
Send documents and processing instructions via HTTP requests
The server responds with your processed documents
Use Instant JSON to create new annotations like text, images, and outlines. Add a new cover page to a PDF; create new PDFs from selected pages; or move, rotate, and delete pages.
Guides
Import annotations or fill in form values easily by applying XFDF files to your PDF documents.
Guides
Convert Word, Excel, PowerPoint, text, and OpenOffice files to PDF. Plus, populate DOCX templates with your data to generate custom Word or PDF documents.
Guides
Use Processor to automate OCR workflows and make text in raster and vector PDFs accessible.
Guides
Define presets and rules to automate permanent removal of text and image data. Includes rules for common personally identifiable information types.
Guides
Convert JPG, PNG, HEIC, GIF, BMP, WEBP, SVG, TGA, EPS, DXF, and TIFF files to PDF. You can also annotate and edit JPG and PNG files with the same tools you use for PDFs without converting to PDF.
Guides

Enhance your user experience with PDF Linearization, allowing instant access to content in the browser as full documents load seamlessly.
Compress PDFs using an engine yielding compact, top-tier mixed raster content (MRC) documents.
Convert PDFs into the veraPDF and ISO-compliant document preservation format PDF/A without compromising on quality or accessibility.

All of PSPDFKit’s document processing prowess, no complicated backend, easy to use, and easy to scale. Cool, right?
Processor doesn’t store any document data or information internally. You remain in complete control of your documents at all times.
Our simplified API exposes all the document processing operations included in your license — like page rotation, deletion and creation, applying XFDF or Instant JSON, and document flattening. Additionally, you can extract text with our OCR component.
Without the need for a backend database or dedicated storage, deployment is a breeze.


PSPDFKit Processor, Libraries for Java and .NET, and Server were created with different use cases in mind. Check out the short comparison below to see which one is for you.