Performance Evaluation of Linked Lists


It’s common for even the best programmers to make simple mistakes. To guard against this, the Android codebase at PSPDFKit uses Error Prone, a tool released by Google, to augment the compiler’s type analysis and catch mistakes before they either cost us time or end up as bugs in production.
Today we’ll delve into the performance evaluation of LinkedLists, a controversial topic among many experienced developers, and we’ll try to understand why using LinkedLists triggers a warning in the Error Prone report.
I’ll begin by quoting part of the explanation provided from Error Prone:
“LinkedList almost never out-performs ArrayList or ArrayDeque. If you are using LinkedList as a list, prefer ArrayList. If you are using LinkedList as a stack or queue/deque, prefer ArrayDeque.
Migration gotcha: LinkedList permits null elements; ArrayDeque rejects them. The documentation for Deque strongly discourages users from inserting null, even into implementations that permit it. So, if you are using a LinkedList for this purpose, you should likely stop, and you will need to stop in order to migrate to ArrayDeque.”
The statement above makes it loud and clear that LinkedList should be replaced by ArrayList or ArrayDeque and that null elements should be avoided. But at the same time, it creates more questions than answers: It provides neither tangible data nor a deep explanation for understanding why LinkedLists almost never outperform ArrayLists or ArrayDeques. It also does not explain the rare edge cases where using LinkedLists might be more convenient. This is a great example of how writing good benchmark tests can shed some light on the matter and provide some actual numbers about the performance of our implementation.
Let the Benchmarks Begin
Even if it’s the best way to collect some real data about the performance of your code, benchmarking in Java is a delicate process that requires some finesse: The JVM’s JIT can easily invalidate benchmark results, and one of the most common examples is that of dead code elimination. A full discussion of these issues is provided in this article from Oracle. An easy solution for writing benchmarks correctly is to use JMH, the Java (Micro)benchmark Harness. It tries very hard to prevent the JIT from invalidating your benchmark, and it’s also quite rigorous in measuring and collecting data.
Another issue comes up with System.nanoTime(): While it reports its results in units of nanoseconds, it’s not necessarily precise enough to measure things with a granularity of nanoseconds. The reasons are quite complex, but for a full explanation of the issues with nanoTime(), see Nanotrusting the Nanotime, an article by the Oracle performance guru Aleksey Shipilëv, who is also the author of JMH. The upshot is that you can’t use nanoTime() to measure an operation that runs very quickly. An easy test to verify this can be done by measuring very quick operations: A normal JVM benchmark will report results of around 36-38 ns, whereas the JMH-reported results will be around 3 ns.
The last issue is with the ArrayList itself: If not specified, the initial length is 10. When the limit is reached, there is a 50 percent growth policy, the cost of which will affect the results.
Set Up the Project
An interesting starting point can be found in the GitHub article Ken Fogel’s collections benchmarks rewritten in JMH. To correctly set up the project and learn more about JMH, check out this introduction to JMH. JMH is Maven-based, but luckily, a good Samaritan decided to implement a Gradle plugin.
JMH Options
The suggested options to run the benchmark tests are -wi 5 -i 5 -f 1. In order to translate the options into Gradle options, just type the following:
jmh {
//Options
}Warmup Iterations
-wi <int> Number of warmup iterations to do. Warmup iterations
are not counted toward the benchmark score.Suggested 5 default 20
Gradle option: warmupIterations = 5
Measurement Iterations
-i <int> Number of measurement iterations to do. Measurement
iterations are counted toward the benchmark score.Suggested 5 default 20
Gradle option: iterations = 5
Forks
-f <int> How many times to fork a single benchmark. Use `0` to
disable forking altogether. Warning: Disabling
forking may have a detrimental impact on benchmark
and infrastructure reliability, so you might want
to use a different warmup mode instead.Suggested 1 default 10
Gradle options: fork = 1
Run the Project
To run the project, type ./gradlew jhm.
The actual results are as follows:
Benchmark (SIZE) Mode Cnt Score Error Units SequenceTests.AD_accessFirst 10000 avgt 5 2.761 ± 0.162 ns/op SequenceTests.AD_accessLast 10000 avgt 5 3.324 ± 0.033 ns/op SequenceTests.AD_editFirst 10000 avgt 5 4.556 ± 0.037 ns/op SequenceTests.AD_editLast 10000 avgt 5 5.422 ± 0.062 ns/op SequenceTests.AL_accessFirst 10000 avgt 5 2.626 ± 0.029 ns/op SequenceTests.AL_accessLast 10000 avgt 5 2.802 ± 0.028 ns/op SequenceTests.AL_accessMiddle 10000 avgt 5 2.808 ± 0.027 ns/op SequenceTests.AL_editFirst 10000 avgt 5 929.768 ± 7.320 ns/op SequenceTests.AL_editLast 10000 avgt 5 13.974 ± 0.125 ns/op SequenceTests.AL_editMiddle 10000 avgt 5 429.727 ± 3.960 ns/op SequenceTests.LL_accessFirst 10000 avgt 5 2.558 ± 0.013 ns/op SequenceTests.LL_accessLast 10000 avgt 5 2.887 ± 0.021 ns/op SequenceTests.LL_accessMiddle 10000 avgt 5 6267.620 ± 85.089 ns/op SequenceTests.LL_editFirst 10000 avgt 5 7.545 ± 0.113 ns/op SequenceTests.LL_editLast 10000 avgt 5 11.725 ± 0.068 ns/op SequenceTests.LL_editMiddleIndx 10000 avgt 5 13235.446 ± 210.193 ns/op SequenceTests.LL_editMiddleIter 10000 avgt 5 6544.322 ± 491.544 ns/op
Here is a better visual of the report.
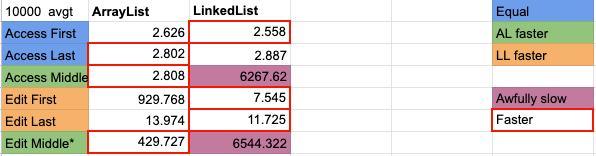
The result is that accessing the middle of an ArrayList is faster than accessing the middle of a LinkedList to an order of 2,000, and editing an element in the middle is faster on an ArrayList to an order of 15.
Sorting
LinkedList implements the List interface, so it can be sorted using Collection.sort(). This method uses an efficient strategy to handle this sorting scenario. It first copies the contents of LinkedList to an array, and then it sorts the array and copies it back. So it’s as efficient as sorting an ArrayList; what’s more taxing is the final addition to the original data structure.
We can dive in to the source code to better comprehend the algorithm used.
The source code of ArrayList#sort(Comparator<? super E>) is:
public void sort(Comparator<? super E> c) { final int expectedModCount = modCount; Arrays.sort((E[]) elementData, 0, size, c); if (modCount != expectedModCount) { throw new ConcurrentModificationException(); } modCount++; }
The main operation here is Arrays.sort((E[]) elementData, 0, size, c), which sorts all the ElementData according to the comparator c.
The source code of LinkedList#sort(Comparator<? super E>) instead contains one more step:
default void sort(Comparator<? super E> c) { Object[] a = this.toArray(); Arrays.sort(a, (Comparator) c); ListIterator<E> i = this.listIterator(); for (Object e : a) { // <-- Iterate all the elements and copy them back to their original data structure. i.next(); i.set((E) e); } }
After sorting the elements, they are copied back into the original data structure. So if we end up comparing the time of the actual sort, we’re going to have an exact match because we’d run the same method on the same data structure: Arrays#sort(T[], Comparator<? super T>):
Benchmark (initialSize) Mode Cnt Score Error Units SortTests.AL_sortingNewArray 10 avgt 5 88.072 ± 1.725 ns/op SortTests.LL_sortingNewArray 10 avgt 5 97.546 ± 2.254 ns/op SortTests.AL_sortingNewArray 100 avgt 5 1898.153 ± 148.661 ns/op SortTests.LL_sortingNewArray 100 avgt 5 1905.910 ± 50.959 ns/op SortTests.AL_sortingNewArray 1000 avgt 5 75611.107 ± 23686.507 ns/op SortTests.LL_sortingNewArray 1000 avgt 5 67038.743 ± 1312.114 ns/op
The small delta that introduces the slight difference of around 8 ns is due to how ArrayList and LinkedList implement the method toArray(), but we can conclude that the amount of time used is almost the same.
ArrayList Initial Size
To avoid performance degradation, the initial size of the ArrayList plays an important role. Here is a benchmark about ArrayList creation with different initial sizes:
Benchmark (initialSize) Mode Cnt Score Error Units ArrayListCreation.AL_creation 10 avgt 5 15.058 ± 1.150 ns/op ArrayListCreation.AL_creation 100 avgt 5 43.116 ± 1.408 ns/op ArrayListCreation.AL_creation 500 avgt 5 175.632 ± 5.606 ns/op ArrayListCreation.AL_creation 1000 avgt 5 251.985 ± 10.710 ns/op ArrayListCreation.AL_creation 10000 avgt 5 1789.884 ± 244.084 ns/op ArrayListCreation.AL_creation 100000 avgt 5 19106.937 ± 2898.476 ns/op
OrderedSet Comparison
Now let’s introduce two implementations of the data type OrderedSet.
The first extends ArrayList:
/** * This is a modification of a `{@link ArrayList}`, which removes existing copies of an item in the data structure * before adding it. */ public class OrderedSet<E> extends ArrayList<E> implements Cloneable, Serializable { public OrderedSet(@IntRange(from = 0) int initialCapacity) { super(initialCapacity); } public OrderedSet() { super(); } @Override public boolean add(E object) { super.remove(object); return super.add(object); } }
And the second extends LinkedList:
/** * This is a modification of a `{@link LinkedList}`, which removes existing copies of an item in the data structure * before adding it. */ public class OrderedSet<E> extends LinkedList<E> implements Cloneable, Serializable { public OrderedSet() { super(); } @Override public boolean add(E object) { super.remove(object); return super.add(object); } }
Adding these data types to our JMH project produces the following benchmark with two different OrderedSet implementations:
Benchmark (SIZE) Mode Cnt Score Error Units OrderedSetTests.OrderedSetArrayListAddLast 500 avgt 5 6.567 ± 0.103 ns/op OrderedSetTests.OrderedSetArrayListEditLast 500 avgt 5 12.158 ± 1.272 ns/op OrderedSetTests.OrderedSetLinkedListAddLast 500 avgt 5 9.994 ± 0.408 ns/op OrderedSetTests.OrderedSetLinkedListEditLast 500 avgt 5 21.118 ± 2.380 ns/op
Conclusion
LinkedList<E> allows for constant-time insertions or removals, but only using iterators. In other words, you can walk the list forward or backward, but finding a position in the list takes time proportional to the size of the list. The Java documentation says that “operations that index into the list will traverse the list from the beginning or the end, whichever is closer,” so the methods are O(n), with n/4 steps on average, though O(1) for index = 0
OrderedSet extending ArrayList with a finely tuned value as the initial size proved to be faster for adding and editing elements.
The benchmark project with all the tests presented above is available on GitHub in the PSPDFKit-labs section.



