Rendering PDFs on Android


When building a PDF framework for mobile devices, one of the most important things is user experience, and one of the key factors in delivering a slick user experience is how performant the rendering is.
This article will explain the processes we utilize in our framework on the Android side. The examples will be semi-technical, providing some code, but mostly discussing the UX part of the process and the things we pay attention to when implementing it.
How We Render PDFs
Our PDF rendering is performed in the core (C++) and shared between iOS and Android. What you need to provide from the Android side is context, the page index of the target page, the width and height of the desired bitmap, and the rendering configuration (PageRenderConfiguration). The configuration allows you to do things like render specific regions of the page, get the image in grayscale, invert colors, and cache the bitmap:
fun renderPageToBitmap(
context: Context,
pageIndex: Int,
width: Int,
height:Int,
configuration: PageRenderConfiguration): Bitmappublic Bitmap renderPageToBitmap( @NonNull final Context context, final int pageIndex, final int width, final int height, @NonNull final PageRenderConfiguration configuration)
The Android Side of PDF Rendering
Now the main challenge we need to solve is optimizing the use of this simple API above in order to get the user experience we want. On the Android side we are concerned with reusing bitmaps, rendering images in optimal sizes, avoiding rendering the parts we already had, prioritizing which pages to render first, etc.
Full Pages
The first things we need to render when opening the document are the pages users will browse. First we render a couple of pages (three to five, depending on the device) around the visible page in lower resolution. If we were to render higher-resolution images from the get-go, this would increase the waiting time, and we don‘t want our users to have to wait unnecessarily. Low-res images are relatively cheap when it comes to rendering times, yet they‘re sharp enough for the initial page image that‘ll be displayed before the high-res image comes in.
You may have noticed that we have page thumbnails — used for navigating the document — below the main document view. In addition to the thumbnails, we also provide a page grid view, using preview images that are close in size to the thumbnails mentioned. We can take advantage of this fact by reusing the same images for both, thereby creating a cache of rendered pages we can reuse. This way, we end up having three separate resolutions (low-res, thumbnails/grid, high-res) instead of four (low-res, thumbnails, grid, high-res).
The next thing that comes into play is the high-res image for the viewer. The page a user is currently reading should be clear and sharp, which is why we need a high-res image. But we only render them for the pages that are visible; otherwise, rendering is too expensive. Not only that, but users don‘t see the difference between high-res and low-res images when scrolling through the document. So as soon as the scrolling starts, the high-res image gets removed and the bitmap gets recycled.
Rendering Page Regions
Page regions are parts of the page we need to render in high resolution. Together they form the image that‘s visible when a user zooms in on the page. It is the hardest part of implementation since, if it‘s not managed properly, it can generate a lot of memory problems (heap overflow) and slow rendering times.
So when the page gets zoomed in, we need a part of the page to be re-rendered and placed in the correct location on top of the low-res and high-res full-page images. The naive approach would be to just simply request the visible rectangle on the screen to be rendered. Let‘s see why that is a bad approach:
-
The user zooms in and then waits some time without any indication that the image is being rendered.
-
Once the user begins scrolling on the page, the non-rendered regions show, and they look pretty bad.
-
We have to re-render a region once the scrolling stops, meaning the non-rendered regions are blurry during the entire scrolling process.
-
The new image we need could also overlap with an old image we had, meaning we could be rendering the same image all over again, just in a different place.
-
And so on…
Using Tiled Rendering
To avoid most of the aforementioned problems, we decided to implement a “tiled” or “grid” rendering. This means splitting the screen in tiles and just rendering the parts of the pages covered by those tiles. This works by splitting the screen in a pre-defined number of tiles. We decided to go with 12 (4x3), because having more tiles means more rendering calls when moving around (which equates to more C++ calls). You can play with that number and try to optimize it for your own implementation.
Now while scrolling around, append new tiles to the tiles that are already rendered. At the same time, remove those that are no longer visible. By using the previously mentioned bitmap pools, this approach will provide you with a fixed pool of tiles and will not allocate and deallocate memory unnecessarily.
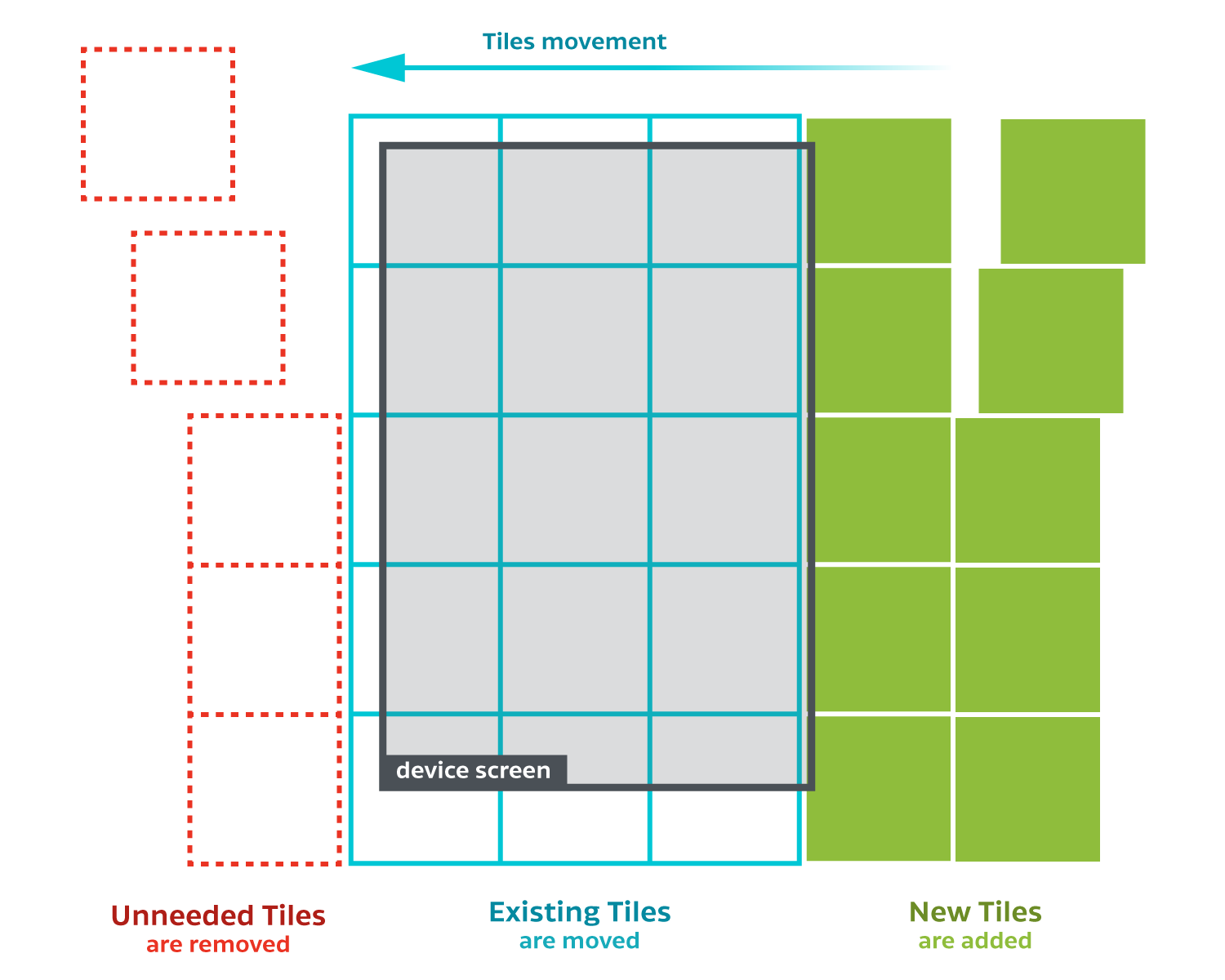
This way we can asynchronously request rendering as soon as a tile becomes visible, despite the scrolling action running on the main thread. We can do this because the size we need and the region we need to render are determined. If we were to render the region as a whole, as soon as the rendering is requested, the region that needs to be shown would already be invalidated due to the scrolling. With tiles, you still need the same image, but you just reposition the tile.
Another thing we need to keep in mind is the zoom level of the PDF document. This and the current scroll position are the variables needed to calculate which parts of the page need to be rendered. Now, since we define tiles based on the screen size and not the relative page size, we still get to use tile bitmaps from the old zoom scale, but we just need to recalculate the new region.
Quick showcase (green tiles are the ones being scheduled for rendering):



