Top 10 Ways to Generate PDFs in Python
 Hulya Masharipov
Hulya Masharipov

PDFs have become an essential format across various industries due to their ability to preserve document formatting and ensure consistent viewing experiences. Their versatility allows for use in business reports, contracts, invoices, and ebooks. Python developers often need to generate PDFs for various purposes, such as creating reports, invoices, or forms.
In this article, you’ll discover 10 ways to generate PDFs in Python, focusing on open source libraries that cater to different needs.
You’ll gain insights into various libraries available for Python PDF generation, understanding their features and practical use cases. By exploring these options, you can select the most suitable library for your project requirements and streamline the PDF generation process effectively.
1. Generating PDFs with FPDF
FPDF is a lightweight PDF generation library for Python that allows you to create PDFs from scratch. It’s particularly well-suited for generating simple PDFs with text, images, and basic formatting. FPDF is easy to use and doesn’t have any external dependencies.
Key Features
-
Text and image insertion — Easily add text, images, and lines to your PDF.
-
Multipage PDFs — Create multipage PDFs with simple commands.
-
Formatting options — Customize fonts, colors, and text alignment.
-
Lightweight and fast — FPDF is efficient and requires no external dependencies.
Installation
You can install FPDF using pip:
pip install fpdf
Usage Example
Here’s a simple example of how to create a PDF with FPDF:
from fpdf import FPDF # Create instance of FPDF class. pdf = FPDF() # Add a page. pdf.add_page() # Set font. pdf.set_font("Arial", size=12) # Add a cell. pdf.cell(200, 10, txt="Hello, this is a PDF generated using FPDF!", ln=True, align='C') # Save the PDF with name `.pdf`. pdf.output("output.pdf") print("PDF generated successfully!")
In this example, you created a PDF document, added a single page, and inserted a line of centered text. The PDF was then saved to a file named output.pdf. FPDF provides a simple and effective way to generate PDFs with basic content and formatting.
When to Use FPDF
FPDF is ideal for applications where you need to generate simple PDFs quickly and without external dependencies. It’s a great option when you need to create multipage documents with text, images, and basic layout control.
2. Generating PDFs with ReportLab
ReportLab is an open source Python library designed for creating and manipulating PDF documents. It’s known for its robustness and flexibility, making it a powerful tool for generating complex documents and reports programmatically.
Key Features
-
PDF generation — Easily create PDFs with text, images, charts, and custom graphics.
-
Advanced graphics — Provides tools for drawing complex layouts and graphical elements.
-
Document templates — Supports using templates to streamline the creation of consistent document formats.
-
Custom fonts and styles — Allows fine-tuned control over document appearance with custom fonts and styling options.
Licensing
ReportLab offers a Community Edition under the ReportLab Open Source License, which is free and suitable for most non-commercial uses. For commercial applications and additional features, ReportLab also provides a Commercial Edition with extended capabilities and support.
Installation
To install ReportLab, use pip:
pip install reportlab
Usage Example
Here’s a basic example of how to generate a PDF using ReportLab:
from reportlab.lib.pagesizes import letter from reportlab.pdfgen import canvas # Create a PDF file. c = canvas.Canvas("example.pdf", pagesize=letter) # Draw some text. c.drawString(100, 750, "Hello, this is a PDF generated with ReportLab!") # Save the PDF. c.save()
In this example, a PDF file named example.pdf is created with a simple line of text. ReportLab’s capabilities extend far beyond this example, allowing for the creation of complex and professional documents.
When to Use ReportLab
ReportLab is ideal for generating detailed and customized PDF documents where precise control over layout and content is required. It’s especially useful for creating reports, invoices, and other professional documents that require sophisticated formatting and graphical elements.
3. Generating PDFs with PDFKit
PDFKit is a Python library that simplifies the process of converting HTML to PDF using the wkhtmltopdf command-line tool. It allows you to generate high-quality PDFs from HTML content, making it suitable for scenarios where you need to create PDFs from web-based content or styled documents.
Key Features
-
HTML-to-PDF conversion — Convert HTML and CSS content into well-formatted PDF documents.
-
Support for complex layouts — Handle complex HTML structures and CSS styles effectively.
-
Easy integration — Simple to integrate into Python applications for generating PDFs.
Installation
To use PDFKit, you need to install both the pdfkit library and the wkhtmltopdf tool. Follow the steps below to set it up.
-
Install the PDFKit library:
pip install pdfkit
-
Download and install
wkhtmltopdffrom its official website, or use a package manager.
-
For macOS (Homebrew):
brew install wkhtmltopdf
-
For Ubuntu/Debian:
sudo apt-get install wkhtmltopdf
-
For Windows:
Download the installer from the official site and follow the installation instructions.
Converting HTML to PDF
Here’s a simple guide for converting an HTML file into a PDF:
import pdfkit # Specify the path to your HTML file. html_file = 'example.html' # Define the output PDF file name. output_pdf = 'output.pdf' # Convert HTML to PDF. pdfkit.from_file(html_file, output_pdf)
This straightforward approach makes PDFKit an appealing choice for generating PDFs from existing web content. Its ease of use combined with powerful features positions it effectively among the top libraries for PDF generation in Python.
To learn more about converting HTML to PDF using Python, check out our blog post:
4. Generating PDFs with WeasyPrint
WeasyPrint is a Python library that converts HTML and CSS into high-quality PDF documents. It leverages modern web standards to ensure the resulting PDFs maintain the same layout and styling as the HTML source, making it a great tool for generating print-ready documents.
Key Features
-
HTML- and CSS-to-PDF conversion — Supports complex HTML and CSS, including modern layout techniques.
-
Advanced styling — Handles stylesheets and responsive design effectively.
-
Unicode and multilingual support — Includes comprehensive support for different languages and character sets.
-
SVG support — Allows embedding and rendering of SVG graphics in PDFs.
Installation
To use WeasyPrint, you need to install the weasyprint library along with its dependencies.
Here’s how to install it:
pip install weasyprint
WeasyPrint also requires some additional system dependencies for full functionality. On macOS, Ubuntu/Debian, or Windows, ensure you have the necessary packages installed. For Ubuntu/Debian, you might need:
sudo apt-get install libffi-dev libpq-dev
Usage Example
To illustrate the capabilities of WeasyPrint, consider the following example that generates a styled PDF document:
from weasyprint import HTML # Define HTML content. html_content = ''' <!DOCTYPE html> <html> <head> <title>Sample PDF</title> <style> body { font-family: Arial, sans-serif; } h1 { color: #333; } </style> </head> <body> <h1>Hello, this is a PDF generated using WeasyPrint!</h1> <p>This PDF is created from HTML content with CSS styling.</p> </body> </html> ''' # Convert HTML to PDF. HTML(string=html_content).write_pdf("output.pdf") print("PDF generated successfully!")
In this example, HTML(string=html_content).write_pdf("output.pdf") converts the provided HTML content into a PDF file named output.pdf.
When to Use WeasyPrint
WeasyPrint is ideal for generating PDFs from HTML and CSS where accurate rendering and complex styling are required. It’s especially useful for creating reports, invoices, and documents that need to maintain the appearance and layout defined in web standards.
To learn more about WeasyPrint, visit our How to Generate PDF from HTML Using Python blog post.
5. Generating PDFs with Playwright for Python
Playwright for Python is a modern automation library that supports multiple browsers, including Chromium, Firefox, and WebKit. It allows you to perform end-to-end testing and automation of web applications and can also be used to generate PDFs from web pages.
Key Features
-
Cross-browser support — Works with Chromium, Firefox, and WebKit for consistent results across different browsers.
-
PDF generation — Render web pages to PDF with precise control over layout and styling.
-
Headless mode — Operate in headless mode for faster and more efficient rendering.
-
Rich APIs — Provides extensive APIs for interacting with web pages, including taking screenshots and generating PDFs.
Installation
To use Playwright for Python, you need to install the playwright library and its necessary dependencies. Read on to learn how to install it.
-
Install Playwright:
pip install playwright
Usage Example
Here’s a simple example of how to use Playwright to generate a PDF from a web page:
from playwright.sync_api import sync_playwright # Initialize Playwright. with sync_playwright() as p: # Launch a browser. browser = p.chromium.launch() # or p.firefox.launch() or p.webkit.launch() page = browser.new_page() # Navigate to a web page. page.goto('https://github.com/microsoft/playwright-python') # Generate PDF from the web page. page.pdf(path='output.pdf', format='A4') # Close the browser. browser.close() print("PDF generated successfully!")
In this example, Playwright navigates to https://github.com/microsoft/playwright-python, generates a PDF of the page, and saves it as output.pdf.
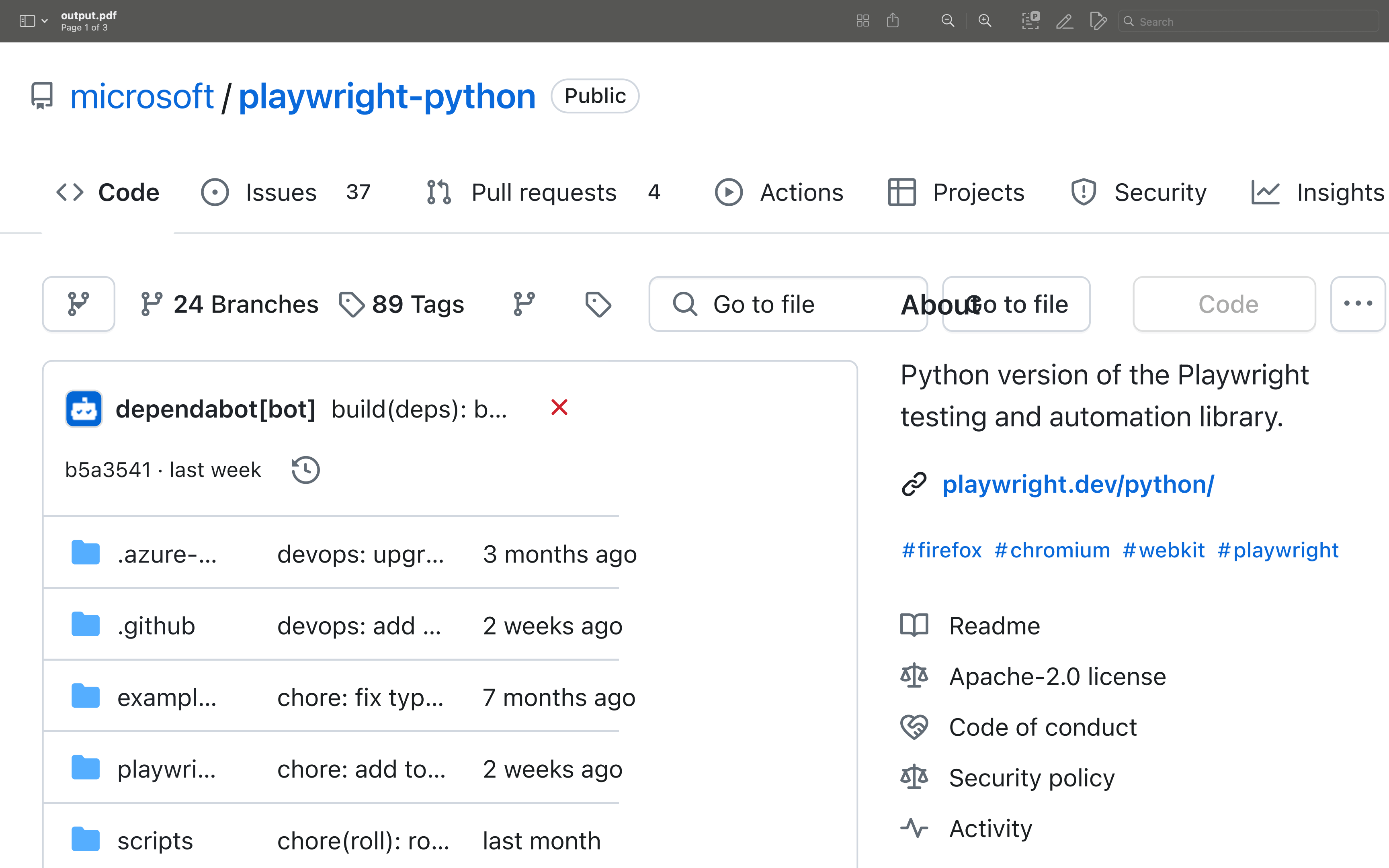
When to Use Playwright
Playwright is ideal for generating PDFs from dynamic web pages, where you need to capture the final rendered state of a page, including complex layouts and JavaScript-rendered content. It’s also useful for testing and automation tasks where PDF generation is required as part of end-to-end testing workflows.
6. Generating PDFs with img2pdf
img2pdf is a lightweight Python library that converts images into PDF documents. It’s ideal for scenarios where you need to create a PDF from one or more image files, such as scanned documents, photographs, or graphics.
Key Features
-
Image-to-PDF conversion — Convert various image formats (e.g. JPEG, PNG, TIFF) to PDF.
-
Support for multiple images — Combine multiple images into a single PDF document.
-
Lossless compression — Maintains the quality of images without unnecessary compression.
-
Simple API — Provides an easy-to-use interface for straightforward image-to-PDF conversion.
Installation
To use img2pdf, install the library using pip:
pip install img2pdf
Usage Example
Here’s a basic example of how to use img2pdf to convert images to a PDF:
import img2pdf # List of image file paths. image_files = ['image1.jpg', 'image2.png', 'image3.tiff'] # Convert images to PDF. with open('output.pdf', 'wb') as f: f.write(img2pdf.convert(image_files)) print("PDF generated successfully!")
In this example, img2pdf.convert() takes a list of image file paths and writes them into a PDF file named output.pdf.
When to Use img2pdf
img2pdf is ideal for creating PDFs from image files when you need to preserve image quality and handle multiple images in a straightforward manner. It’s particularly useful for compiling scanned documents, photo albums, or any other collection of images into a single PDF document.
7. Using Pillow with img2pdf
Pillow is a popular Python library for image processing, offering features like resizing, cropping, and filtering images. When combined with img2pdf, you can preprocess images before converting them into a PDF, giving you more control over a document’s final appearance.
Key Features
-
Image manipulation — Resize, crop, rotate, or apply filters to images before conversion.
-
Format conversion— Convert images to different formats (e.g. JPEG, PNG) as needed before creating a PDF.
-
Seamless integration— Use Pillow to preprocess images and then pass them directly to img2pdf for PDF generation.
Installation
To use Pillow with img2pdf, install both libraries using pip:
pip install Pillow img2pdf
Example Code
Here’s an example of how to use Pillow and img2pdf together to preprocess images and convert them into a PDF:
from PIL import Image import img2pdf # Open an image using Pillow. image = Image.open('input.jpg') # Resize the image (optional). image = image.resize((800, 600)) # Convert the image to another format if needed (optional). image = image.convert('RGB') # Save the modified image temporarily. image.save('modified_image.jpg') # Convert the modified image to PDF. with open('output.pdf', 'wb') as f: f.write(img2pdf.convert('modified_image.jpg')) print("PDF generated successfully!")
In this example:
-
Pillow is used to open an image and apply some basic processing, such as resizing and format conversion.
-
The processed image is then saved temporarily before being passed to img2pdf for PDF conversion.
When to Use Pillow with img2pdf
This combination is ideal when you need to preprocess images before converting them into PDFs. For example, if you need to standardize image sizes, apply filters, or adjust colors before creating a PDF, Pillow provides the necessary tools, while img2pdf ensures high-quality conversion.
8. Generating PDFs with xhtml2pdf
xhtml2pdf is a Python library that simplifies the process of converting HTML and CSS documents into PDFs. It allows you to leverage web technologies to design and style your documents, which can then be converted into high-quality PDF files. This makes it a great choice for applications where you need to dynamically generate PDFs from HTML content, such as web-based reports, invoices, or brochures.
Key Features
-
HTML-to-PDF conversion — Converts HTML documents into PDFs while preserving the layout and styles defined in the CSS.
-
Support for complex layouts — Handles multipage documents, headers, footers, and various CSS properties to create professional-looking PDFs.
-
Embedded fonts and images — Supports embedding fonts and images in the PDF, ensuring the final document matches the original design.
Installation
To use xhtml2pdf, you can install it via pip:
pip install xhtml2pdf
Usage Example
Here’s a simple example of how to convert an HTML file to a PDF using xhtml2pdf:
from xhtml2pdf import pisa # Define a function to convert HTML to PDF. def convert_html_to_pdf(source_html, output_filename): # Open output file for writing (binary mode). with open(output_filename, "wb") as output_file: # Convert HTML to PDF. pisa_status = pisa.CreatePDF(source_html, dest=output_file) # Return `true` if the conversion was successful. return pisa_status.err == 0 # HTML content to be converted. html_content = """ <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Sample PDF</title> <style> h1 { color: #2E86C1; } p { font-size: 14px; } </style> </head> <body> <h1>Hello, PDF!</h1> <p>This is a PDF generated from HTML using xhtml2pdf.</p> </body> </html> """ # Convert HTML to PDF. if convert_html_to_pdf(html_content, "output.pdf"): print("PDF generated successfully!") else: print("PDF generation failed!")
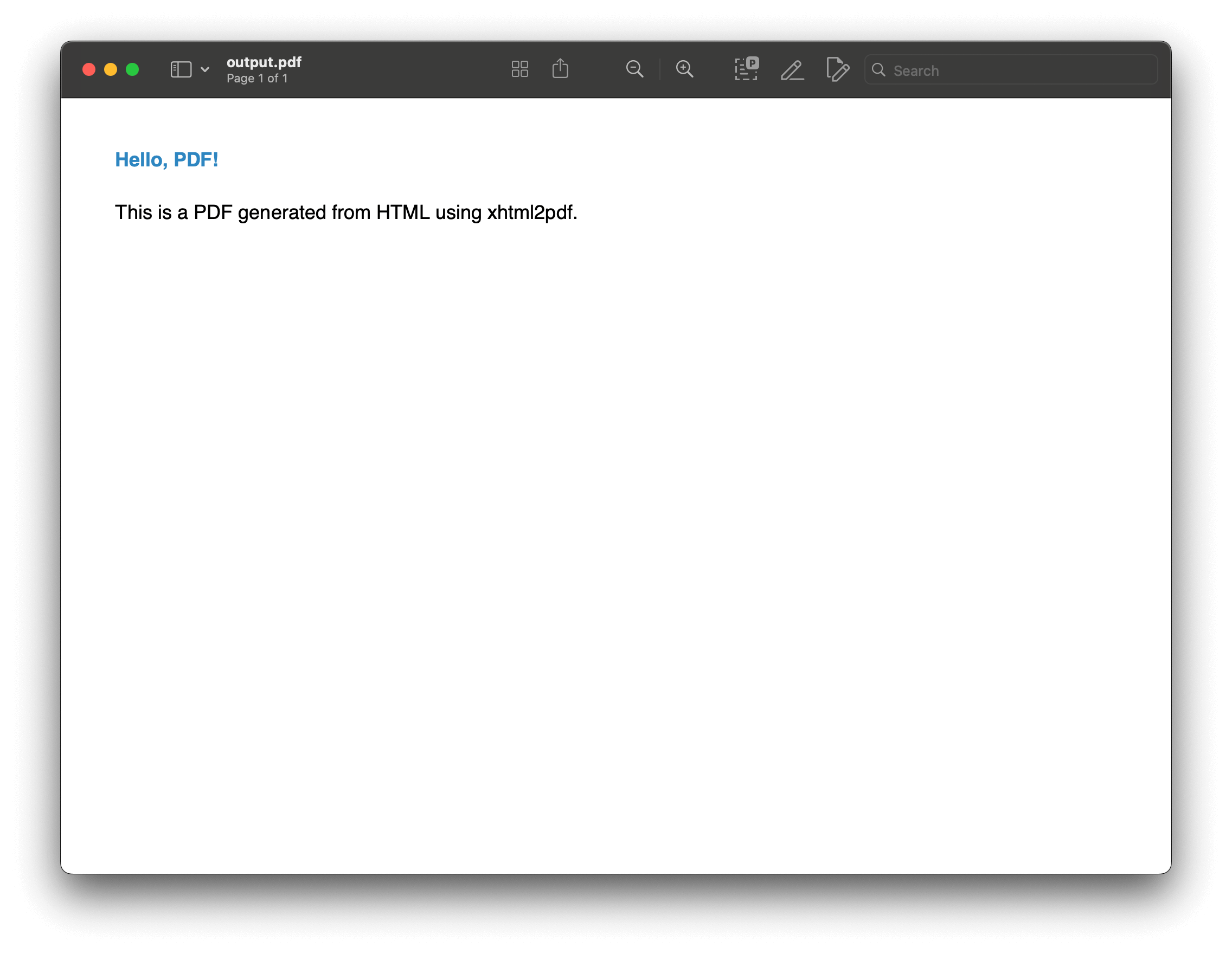
In this example, xhtml2pdf is used to convert a simple HTML string into a PDF file named output.pdf. The library handles the HTML structure and CSS styling, allowing you to produce a well-formatted PDF.
When to Use xhtml2pdf
xhtml2pdf is particularly useful when you need to generate PDFs from web content or HTML templates. It’s a great option for web applications where PDF generation is needed for reports, invoices, or other documents that are naturally represented in HTML. If you’re already comfortable with HTML and CSS, xhtml2pdf provides a straightforward way to translate your web designs into printable PDF files.
9. Generating PDFs with pdfdocument
pdfdocument is a straightforward Python library designed for generating PDFs with minimal setup and complexity. It offers a simple API to create PDF files, making it ideal for cases where you need to generate PDFs quickly without dealing with the intricacies of more complex libraries like ReportLab or WeasyPrint.
Key Features
-
Easy to use — The API is designed to be intuitive, allowing you to create PDFs with just a few lines of code.
-
Basic PDF content — Supports adding text, images, and basic formatting to your PDFs.
-
Lightweight — The library is lightweight, making it a good choice for simple use cases where you don’t need advanced features.
Installation
You can install pdfdocument via pip:
pip install pdfdocument
Usage Example
Here’s a simple example of how to use pdfdocument to generate a PDF:
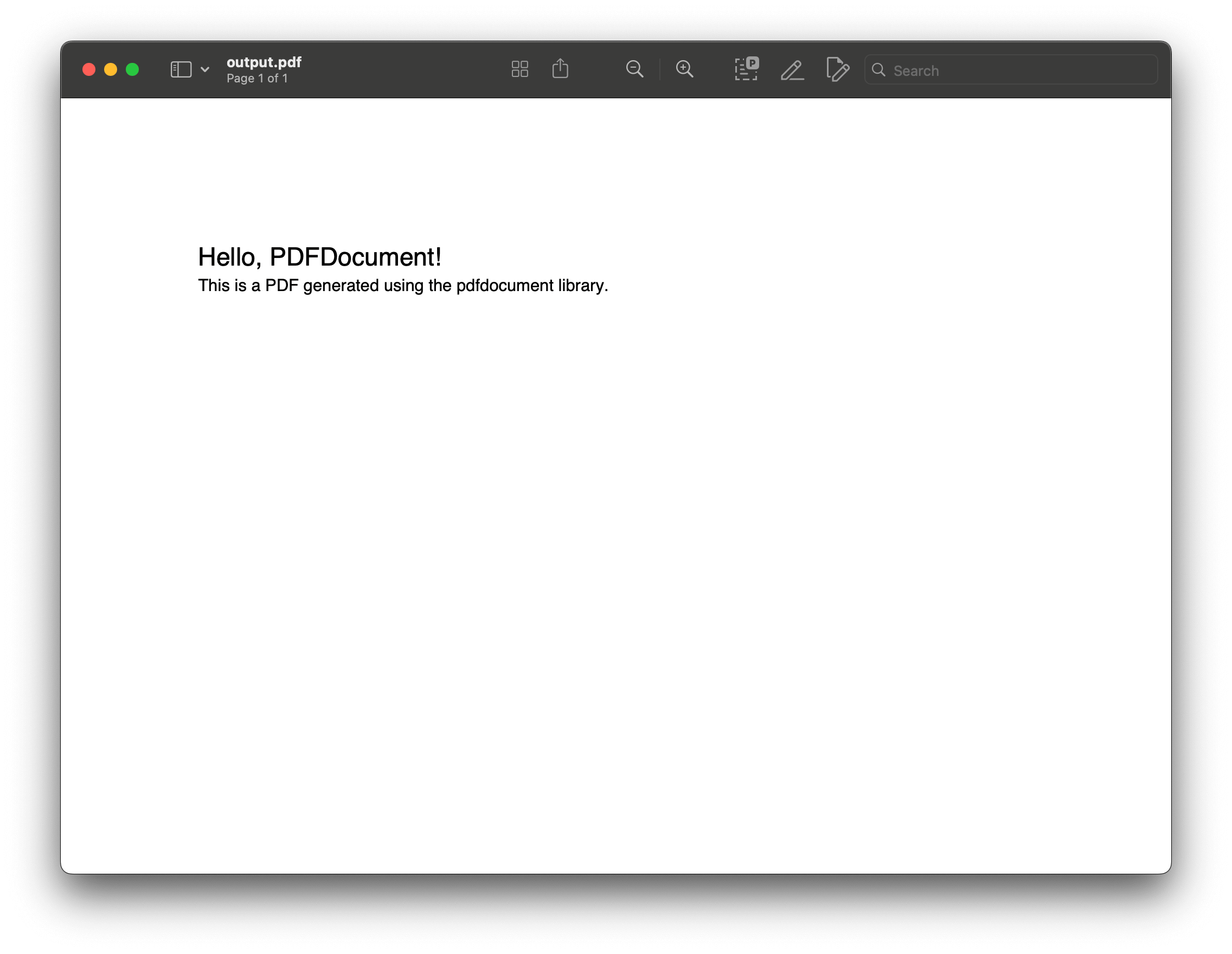
from pdfdocument.document import PDFDocument # Create a PDF document. pdf = PDFDocument("output.pdf") # Start the PDF. pdf.init_report() # Add a title and some text. pdf.h1("Hello, PDFDocument!") pdf.p("This is a PDF generated using the pdfdocument library.") # Add an image (optional). # pdf.image("path_to_image.jpg", width=200) # Finalize and save the PDF. pdf.generate() print("PDF generated successfully!")
In this example, pdfdocument is used to create a PDF file named output.pdf. The code adds a title and a paragraph of text, demonstrating how easily you can generate a basic PDF. The generate() method finalizes and saves the document.
Advanced Usage
-
Simple reports — The
init_report()method initializes the PDF as a report, but you can customize this to suit different document types. -
Adding images — You can easily insert images into the PDF, making it suitable for generating simple visual reports or documents with logos.
-
Customization — While pdfdocument is simple, you can still apply basic formatting, such as different heading levels and paragraphs.
When to Use pdfdocument
pdfdocument is ideal for scenarios where you need to generate PDFs quickly and don’t require complex layouts or advanced formatting. It’s a good fit for applications that need to create simple reports, letters, or any other document that doesn’t require extensive customization. If you’re looking for a no-fuss solution for basic PDF generation, pdfdocument is a great tool to consider.
10. Generating PDFs with PSPDFKit API
PSPDFKit is a robust and feature-rich API designed for working with PDFs. It offers comprehensive capabilities for creating, editing, annotating, and processing PDF documents. Although PSPDFKit is a commercial product, its powerful API makes it a valuable tool for developers who need advanced PDF functionalities beyond basic generation.
Key Features
-
High-quality PDF rendering — Generates PDFs that are accurate and visually consistent across platforms.
-
Advanced PDF features — Supports complex PDF operations, including form filling, digital signatures, annotations, and more.
-
REST API — The API is platform-agnostic, allowing you to interact with it from any environment, including Python, via HTTP requests.
-
Customization — Offers extensive options for customizing PDF output, including fonts, layouts, and security settings.
Installation
To use the PSPDFKit API, you need to sign up for an API key and use the provided endpoints. There’s no need for a specific Python package, as you can interact with the API using HTTP requests, typically via libraries like requests.
Example Code
Here’s an example of how to generate a PDF using PSPDFKit’s PDF Generator API in Python:
import requests import json # Define the HTML part of the document. instructions = { 'parts': [ { 'html': 'index.html' } ] } # Send the request to the PSPDFKit API. response = requests.request( 'POST', 'https://api.pspdfkit.com/build', headers={ 'Authorization': 'Bearer {YOUR_API_KEY}' # Replace with your API key. }, files={ 'index.html': open('index.html', 'rb'), }, data={ 'instructions': json.dumps(instructions) }, stream=True ) # Save the resulting PDF. if response.ok: with open('result.pdf', 'wb') as fd: for chunk in response.iter_content(chunk_size=8096): fd.write(chunk) else: print(response.text) exit()
To generate a PDF, the instructions dictionary specifies that the PDF should be generated from the index.html file. The code then sends a POST request to the PSPDFKit API with the HTML content. The API processes this data and returns a PDF file. If the request is successful, the PDF is saved as result.pdf. If there’s an error, the response is printed for troubleshooting.
Getting Started
-
Sign up — Visit the PSPDFKit website and sign up for an account.
-
Request an API key — After signing up, obtain an API key from the dashboard.
-
Pricing — PSPDFKit offers flexible pricing based on your needs. You can start with a trial period and then choose a plan that fits your requirements.
When to Use PSPDFKit API
The PSPDFKit API is ideal for developers needing a robust, scalable solution for PDF generation, particularly when working with complex documents or requiring extensive customization.
Advanced Usage
-
Dynamic PDF content — Combine the API with dynamic data sources to generate customized PDFs on the fly, such as invoices, reports, or certificates.
-
Integration with other services — Use the API in conjunction with other PSPDFKit services, such as annotation or form filling, to create comprehensive PDF solutions.
-
Scalability — The API is designed to handle large-scale PDF generation tasks, making it suitable for enterprise-level applications.
Conclusion
This article covered 10 methods for generating PDFs in Python — from simple tools like FPDF and img2pdf, to advanced options like ReportLab, WeasyPrint, and PSPDFKit.
Each library has features suited to different use cases, such as creating basic documents or complex PDFs with custom styling. Incorporating these strategies into your Python projects elevates your application’s functionality.
While PSPDFKit comes at a higher price point than open source libraries, its capabilities may justify the investment for businesses needing robust features not typically available in free alternatives.
FAQ
Here are a few frequently asked questions about generating PDFs in Python.
Which library should I use for creating simple PDFs with basic content?
FPDF is a lightweight and easy-to-use library that’s perfect for generating simple PDFs with text, images, and basic formatting. It requires no external dependencies and is ideal for straightforward tasks.
Can I generate PDFs with embedded images using Python?
Yes, you can generate PDFs with embedded images using libraries like ReportLab, WeasyPrint, and img2pdf. Each of these libraries provides support for adding images to your PDFs, with img2pdf being specifically designed for converting images to PDFs.
What role does Pillow play when integrated with img2pdf?
Pillow can be used alongside img2pdf to enhance image manipulation before converting images into PDFs. This integration ensures optimal results regarding both quality and file size by allowing developers to preprocess images effectively before conversion.
What features does PSPDFKit API offer for generating PDFs in Python?
PSPDFKit API provides advanced features for generating PDFs, including support for complex layouts, custom styling, and HTML-to-PDF conversion. It allows for creating fillable forms, merging documents, and adding watermarks. Integration with existing Python projects is straightforward, making it a flexible choice for various PDF generation needs.
What features does PDFKit offer for converting HTML to PDF?
PDFKit serves as a wrapper for wkhtmltopdf, enabling the conversion of HTML documents into PDFs while supporting CSS styling and JavaScript execution. This makes it a powerful tool for generating visually appealing PDFs directly from web content.
Hulya is a frontend web developer and technical writer at PSPDFKit who enjoys creating responsive, scalable, and maintainable web experiences. She’s passionate about open source, web accessibility, cybersecurity privacy, and blockchain.



