How to Split PDFs Using Python
 Vyom Srivastava
Vyom Srivastava

In this post, you’ll learn how to split PDF files using our Split PDF Python API. With this API, you can split up to 100 PDF files per month for free. All you need to do is create a free account to access your API key.
Splitting a PDF document is a common use case when working with PDFs and PDF forms because it enables logical archiving of information. Using a PDF splitting API will allow you to automate the process of splitting documents in your workflow.
A simple example would be a financial services company receiving a single PDF with clients’ personal and financial information, as well as a questionnaire they filled in. By integrating a PDF splitting API into the workflow, it’s easy to automatically split documents into logical parts that can be stored separately.
PSPDFKit API
Document splitting is just one of our 30+ PDF API tools. You can combine our splitting tool with other tools to create complex document processing workflows, such as:
-
Converting MS Office files and images into PDFs and splitting them
-
Performing OCR on documents and splitting them
-
Watermarking and flattening PDFs and splitting them
Step 1 — Creating a Free Account on PSPDFKit
Go to our website, where you’ll see the page below, prompting you to create your free account.
Once you’ve created your account, you’ll be welcomed by the page below, which shows an overview of your plan details.
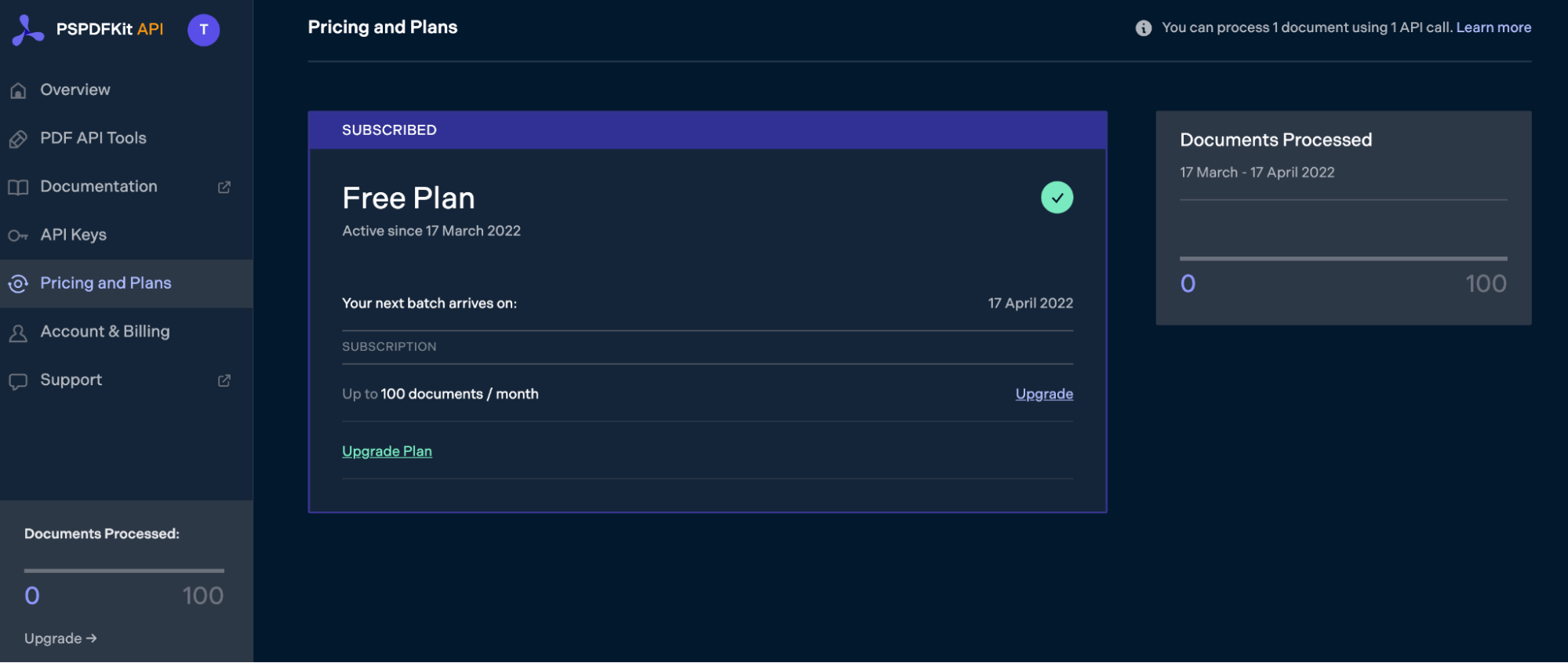
As you can see in the bottom-left corner, you’ll start with 100 documents to process, and you’ll be able to access all our PDF API tools.
Step 2 — Obtaining the API Key
After you’ve verified your email, you can get your API key from the dashboard. In the menu on the left, click API Keys. You’ll see the following page, which is an overview of your keys:
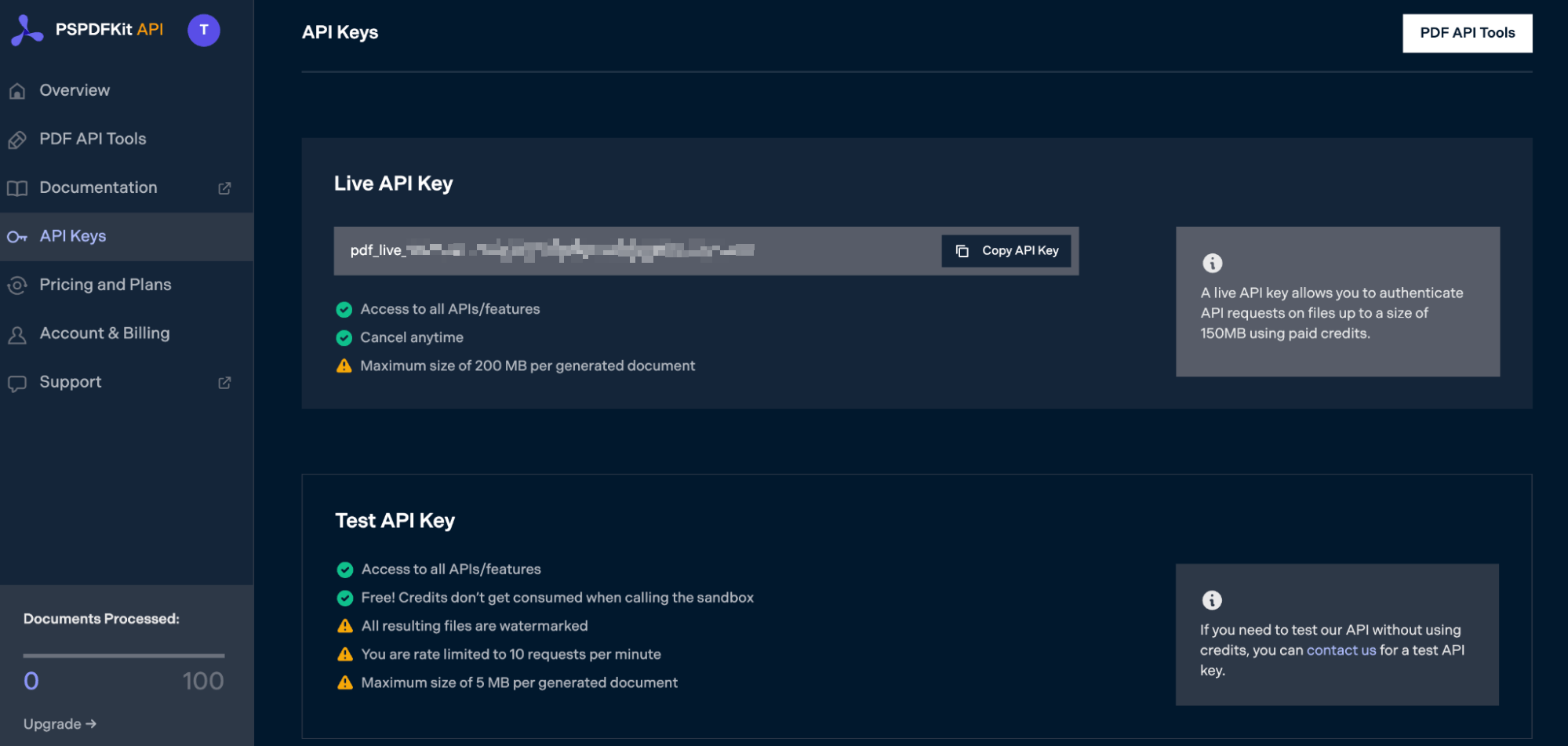
Copy the Live API Key, because you’ll need this for the Split PDF API.
Step 3 — Setting Up Folders and Files
Now, create a folder called split_pdf and open it in a code editor. For this tutorial, you’ll use VS Code as your primary code editor. Next, create two folders inside split_pdf and name them input_documents and processed_documents. Now, copy your PDF to the input_documents folder and rename it to document.pdf.
Then, in the root folder, split_pdf, create a file called processor.py. This is the file where you’ll keep your code.
Your folder structure will look like this:
split_pdf ├── input_documents ├── processed_documents └── processor.py
Step 4 — Writing the Code
Open the processor.py file and paste the code below into it:
import requests import json def process_first_half(): instructions = { 'parts': [ { 'file': 'document', 'pages': { 'end': -6 } } ] } response = requests.request( 'POST', 'https://api.pspdfkit.com/build', headers = { 'Authorization: Bearer YOUR_API_KEY_HERE' # Replace YOUR_API_KEY_HERE with your API key. }, files = { 'document': open('input_documents/document.pdf', 'rb') }, data = { 'instructions': json.dumps(instructions) }, stream = True ) if response.ok: with open('processed_documents/first_half.pdf', 'wb') as fd: for chunk in response.iter_content(chunk_size=8096): fd.write(chunk) else: print(response.text) exit() def process_second_half(): instructions = { 'parts': [ { 'file': 'document', 'pages': { 'start': -5 } } ] } response = requests.request( 'POST', 'https://api.pspdfkit.com/build', headers = { 'Authorization': 'Bearer YOUR_API_KEY_HERE’ }, files = { 'document': open('input_documents/document.pdf', 'rb') }, data = { 'instructions': json.dumps(instructions) }, stream = True ) if response.ok: with open('processed_documents/second_half.pdf', 'wb') as fd: for chunk in response.iter_content(chunk_size=8096): fd.write(chunk) else: print(response.text) exit() process_first_half() process_second_half()
ℹ️ Note: Make sure to replace
YOUR_API_KEY_HEREwith your API key.
Code Explanation
You created two functions: process_first_half and process_second_half. These functions basically do the same thing. First, you created a variable called instructions, which contains instructions for processing the PDF file, such as specifying the offset for your page-splitting operation. After that, you used the requests module to make the API call to our Split PDF API. The result was then saved to the processed_documents folder.
Output
To execute the code, use the command below:
python3 processor.py
Once the code successfully executes, you’ll see two new files in the processed_document folder: first_half.pdf and second_half.pdf. The folder structure will look like this:
split_pdf ├── input_documents ├── processed_documents | └── first_half.pdf | └── second_half.pdf └── processor.py
Final Words
In this post, you learned how to easily and seamlessly split PDF files for your Python application using our Split PDF API.
You can integrate these functions into your existing applications and split PDFs. With the same API token, you can also perform other operations, such as merging documents into a single PDF, adding watermarks, and more. To get started with a free trial, sign up here.



