How to Use Tesseract OCR in Python

In this tutorial, you’ll learn how to perform OCR with Tesseract and Python. In the first part, you’ll use Tesseract OCR to recognize text from images and scanned documents, and in the second part, you’ll use PSPDFKit API to extract text and create searchable PDFs from scanned documents and images.
Optical Character Recognition (OCR) is the process of converting images of text into machine-encoded text. Tesseract OCR is a powerful OCR engine that can be used to recognize text from images or scanned documents. In this blog post, you’ll explore how to use Tesseract OCR in Python.
Tesseract OCR is an open source OCR engine that was originally developed by Hewlett-Packard and is now sponsored by Google. It’s capable of recognizing more than 100 languages and can handle multiple fonts, sizes, and styles of text. Tesseract OCR is widely used in various fields, such as document analysis, automated text recognition, and image processing.
Prerequisites
Before beginning, make sure you have the following installed on your system:
-
Python 3.x
-
Tesseract OCR
The pytesseract package is a wrapper for the Tesseract OCR engine that provides a simple interface to recognize text from images.
Install Tesseract OCR
To install Tesseract OCR on your system, follow the instructions for your specific operating system:
-
Windows — Download the installer from the official GitHub repository and run it.
-
macOS — Use Homebrew by running
brew install tesseract. -
Linux (Debian/Ubuntu) — Run
sudo apt install tesseract-ocr.
You can find more installation instructions for other operating systems here.
Setup
-
Create a new Python file in your favorite editor and name it
ocr.py. -
Download the sample image used in this tutorial here and save it in the same directory as the Python file.
-
Install the pytesseract and Pillow libraries. You can do this using pip3 by running the following command:
pip3 install pytesseract pillow
To verify that Tesseract OCR is properly installed and added to your system’s PATH, open a command prompt (Windows) or terminal (macOS/Linux) and run the following command:
tesseract --version
You’ll see the version number of Tesseract, along with some additional information.
Basic Usage
Now that you’ve installed the pytesseract package, you’ll see how to use it to recognize text from an image.
Import the necessary libraries and load the image you want to extract text from:
import pytesseract from PIL import Image image_path = "path/to/your/image.jpg" image = Image.open(image_path)
Extracting Text from the Image
To extract text from the image, use the image_to_string() function from the pytesseract library:
extracted_text = pytesseract.image_to_string(image)
print(extracted_text)The image_to_string() function takes an image as an input and returns the recognized text as a string.
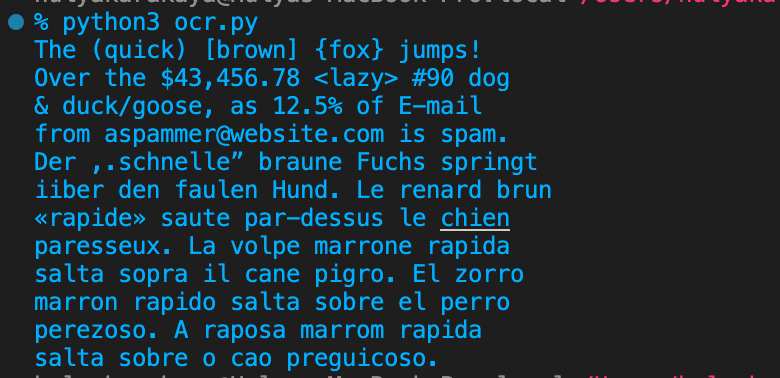
Run the Python script to see the extracted text from the sample image:
python3 ocr.py
You’ll see the output shown below.
Saving Extracted Text to a File
If you want to save the extracted text to a file, use Python’s built-in file I/O functions:
with open("output.txt", "w") as output_file: output_file.write(extracted_text)
Advanced Usage
In addition to the basic usage, the pytesseract package provides several advanced options for configuring the OCR engine, outlined below.
Configuring the OCR Engine
You can configure the OCR engine by passing a configuration string to the image_to_string() function. The configuration string is a set of key-value pairs separated by a space or a newline character.
For example, the following configuration string sets the language to English and enables the PageSegMode mode to treat the image as a single block of text:
config = '--psm 6 -l eng'
text = pytesseract.image_to_string(image, config=config)You can also set the path to the Tesseract OCR engine executable using the pytesseract.pytesseract.tesseract_cmd variable. For example, if the Tesseract OCR engine is installed in a non-standard location, you can set the path to the executable using the following code:
pytesseract.pytesseract.tesseract_cmd = '/path/to/tesseract'Handling Multiple Languages
The Tesseract OCR engine supports more than 100 languages. You can recognize text in multiple languages by setting the language option to a comma-separated list of language codes.
For example, the following configuration string sets the language to English and French:
config = '-l eng+fra'
text = pytesseract.image_to_string(image, config=config)Improving OCR Accuracy with Image Preprocessing
To improve the accuracy of OCR, you can preprocess the image before running it through the OCR engine. Preprocessing techniques can help enhance the image quality and make it easier for the OCR engine to recognize the text.
One common preprocessing technique is to convert the image to grayscale. This can help to improve the contrast between the text and the background. Use the grayscale() method from the ImageOps module of the Pillow library to convert the input image to grayscale:
# Convert image to grayscale
gray_image = ImageOps.grayscale(image)Another preprocessing technique is to resize the image to a larger size. This can make the text in the image larger and easier for the OCR engine to recognize. Use the resize() method from the Pillow library to resize the image:
# Resize the image. scale_factor = 2 resized_image = gray_image.resize( (gray_image.width * scale_factor, gray_image.height * scale_factor), resample=Image.LANCZOS )
In the code above, you’re resizing gray_image to a larger size using a scale factor of 2. The new size of the image is (width * scale_factor, height * scale_factor). This makes use of the Lanczos resampling filter to resize the image, which produces high-quality results.
Another preprocessing technique is to apply adaptive thresholding to the image. Adaptive thresholding can help improve OCR accuracy by creating a more binary image with a clear separation between the foreground and background. Use the FIND_EDGES filter from the ImageFilter module of the Pillow library to apply adaptive thresholding to the image:
# Apply adaptive thresholding.
thresholded_image = resized_image.filter(ImageFilter.FIND_EDGES)Finally, you can pass the preprocessed image to the OCR engine to extract the text. Use the image_to_string() method of the pytesseract package to extract the text from the preprocessed image:
# Extract text from the preprocessed image. improved_text = pytesseract.image_to_string(thresholded_image) print(improved_text)
By using these preprocessing techniques, you can improve the accuracy of OCR and extract text from images more effectively.
Here’s the complete code for the improved OCR script:
from PIL import ImageOps, ImageFilter # Convert image to grayscale. gray_image = ImageOps.grayscale(image) # Resize the image. scale_factor = 2 resized_image = gray_image.resize( (gray_image.width * scale_factor, gray_image.height * scale_factor), resample=Image.LANCZOS ) # Apply adaptive thresholding. thresholded_image = resized_image.filter(ImageFilter.FIND_EDGES) # Extract text from the preprocessed image. improved_text = pytesseract.image_to_string(thresholded_image) print(improved_text)
Recognizing Digits Only
Sometimes, you only need to recognize digits from an image. You can set the --psm option to 6 to treat the image as a single block of text and then use regular expressions to extract digits from the recognized text.
For example, the following code recognizes digits from an image:
import re config = '--psm 6' text = pytesseract.image_to_string(image, config=config) digits = re.findall(r'\d+', text) print(digits)
Here, you import the re module for working with regular expressions. Then, you use the re.findall() method to extract all the digits from the OCR output.
Limitations of Tesseract
While Tesseract OCR is a powerful and widely used OCR engine, it has some limitations and disadvantages that are worth considering. Here are a few of them:
- Accuracy can vary — While Tesseract OCR is generally accurate, the accuracy can vary depending on the quality of the input image, the language being recognized, and other factors. In some cases, the OCR output may contain errors or miss some text altogether.
- Training is required for non-standard fonts — Tesseract OCR works well with standard fonts, but it may have difficulty recognizing non-standard fonts or handwriting. To improve recognition of these types of fonts, training data may need to be created and added to Tesseract’s data set.
- Limited support for complex layouts — Tesseract OCR works best with images that contain simple layouts and clear text. If the image contains complex layouts, graphics, or tables, Tesseract may not be able to recognize the text accurately.
- Limited support for languages — While Tesseract OCR supports many languages, it may not support all languages and scripts. If you need to recognize text in a language that isn’t supported by Tesseract, you may need to find an alternative OCR engine.
- No built-in image preprocessing — While Tesseract OCR can recognize text from images, it doesn’t have built-in image preprocessing capabilities. Preprocessing tasks like resizing, skew correction, and noise removal may need to be done separately before passing the image to Tesseract.
PSPDFKit API for OCR
PSPDFKit’s OCR API allows you to process scanned documents and images to extract text and create searchable PDFs. This API is designed to be easy to integrate into existing workflows, and the well-documented APIs and code samples make it simple to get started.
PSPDFKit’s OCR API provides the following benefits:
- Generate interactive PDFs via a single API call for scanned documents and images.
- SOC 2 compliance ensures workflows can be built without any security concerns. No document data is stored, and API endpoints are served through encrypted connections.
- Access to more than 30 tools allows processing one document in multiple ways by combining API actions such as conversion, OCR, rotation, and watermarking.
- Simple and transparent pricing, where you only pay for the number of documents processed, regardless of file size, datasets being merged, or different API actions being called.
Requirements
To get started, you’ll need:
-
Python 3.x
-
The Requests library
To access your PSPDFKit API key, sign up for a free account. Your account lets you generate 100 documents for free every month. Once you’ve signed up, you can find your API key in the Dashboard > API Keys section.
Python is a programming language, and pip is a package manager for Python, which you’ll use to install the requests library. Requests is an HTTP library that makes it easy to make HTTP requests.
Install the requests library with the following command:
python3 -m pip install requests
Using the OCR API
-
Import the
requestsandjsonmodules:
import requests import json
-
Define OCR processing instructions in a dictionary:
instructions = {
'parts': [{'file': 'scanned'}],
'actions': [{'type': 'ocr', 'language': 'english'}]
}In this example, the instructions specify a single part ("file": "scanned") and a single action ("type": "ocr", "language": "english").
-
Send a
POSTrequest to the PSPDFKit API endpoint to process the scanned document:
response = requests.request(
'POST',
'https://api.pspdfkit.com/build',
headers={
'Authorization': 'Bearer <YOUR API KEY HERE>'
},
files={'scanned': open('image.png', 'rb')},
data={'instructions': json.dumps(instructions)},
stream=True
)Replace <YOUR API KEY HERE> with your API key.
Here, you make a request to the PSPDFKit API, passing in the authorization token and the scanned document as a binary file. You also pass the OCR processing instructions as serialized JSON data.
You can use the demo image here to test the OCR API.
-
If the response is successful (status code
200), create a new searchable PDF file from the OCR-processed document:
if response.ok: with open('result.pdf', 'wb') as fd: for chunk in response.iter_content(chunk_size=8096): fd.write(chunk) else: print(response.text) exit()
Advanced OCR: Merging Scanned Pages into a Searchable PDF with PSPDFKit API
In addition to running OCR on a single scanned page, you may have a collection of scanned pages you want to merge into a single searchable PDF. Fortunately, you can accomplish this by submitting multiple images, with one for each page, to PSPDFKit API.
To test this feature, add more files to the same folder your code is in, and modify the existing code accordingly. You can duplicate and rename the existing file or use other images containing text:
import requests import json instructions = { 'parts': [ { 'file': 'page1.jpg' }, { 'file': 'page2.jpg' }, { 'file': 'page3.jpg' }, { 'file': 'page4.jpg' } ], 'actions': [ { 'type': 'ocr', 'language': 'english' } ] } response = requests.request( 'POST', 'https://api.pspdfkit.com/build', headers = { 'Authorization': 'Bearer <YOUR API KEY HERE>' }, files = { 'page1.jpg': open('page1.jpg', 'rb'), 'page2.jpg': open('page2.jpg', 'rb'), 'page3.jpg': open('page3.jpg', 'rb'), 'page4.jpg': open('page4.jpg', 'rb') }, data = { 'instructions': json.dumps(instructions) }, stream = True ) if response.ok: with open('result.pdf', 'wb') as fd: for chunk in response.iter_content(chunk_size=8096): fd.write(chunk) else: print(response.text) exit()
Replace <YOUR API KEY HERE> with your API key.
The OCR API will merge all of the input files into a single PDF before running OCR on it. The resulting PDF is then returned as the response content.
Conclusion
You learned how to use Tesseract OCR in Python to recognize text from images and scanned documents. You explored basic and advanced usage of the pytesseract package and saw how to configure the OCR engine, handle multiple languages, and improve OCR accuracy with image preprocessing. Additionally, you learned about PSPDFKit’s OCR API and how to integrate it with Python to extract text and create searchable PDFs from scanned documents and images. With these powerful tools at your disposal, you can automate the process of extracting text from documents and images, saving time and improving accuracy.

Hulya is a frontend web developer and technical writer at PSPDFKit who enjoys creating responsive, scalable, and maintainable web experiences. She’s passionate about open source, web accessibility, cybersecurity privacy, and blockchain.




{kind=link}
{kind=link}