How to Flatten a PDF Using Python
 Vyom Srivastava
Vyom Srivastava

In this post, you’ll learn how to programmatically flatten PDFs in Python using our Flatten PDF Python API. With this API, you can flatten up to 100 PDF files per month for free. All you need to do is create a free account to get access to your API key.
Flattening a PDF document is a common use case when working with PDFs and PDF forms. It’s especially crucial when preparing PDF files for printing. This is because PDFs often contain transparent layers that printers can’t detect (e.g. signatures, annotations, transparent objects). In such a case, printers will only print the visible layer. However, flattening a PDF will ensure that all layers are visible to the printer, because the Flatten PDF API will merge them into a single layer.
Additionally, some PDF viewers might not be able to display all types of PDF annotations, so flattening a PDF “bakes in” those annotations, ensuring they’re displayed accurately, regardless of the viewer.
Finally, and most importantly, you can flatten form fields to prevent users from editing or deleting the information input into a PDF form once it’s complete: After a PDF is flattened, the filled-in values will remain in the document, but users won’t be able to edit the fields.
Using PSPDFKit API will allow you to automate the process of flattening documents in your workflow.
PSPDFKit API
Document flattening is just one of our 30+ PDF API tools. You can combine our flattening tool with other tools to create complex document processing workflows, such as:
-
Converting MS Office files and images into PDFs and then flattening them
-
Merging several documents and then flattening the resulting document
-
Adding watermarks and signatures to a document and then flattening them
Once you create your account, you’ll be able to access all our PDF API tools. It’s also important to note that all API tool combinations expend only one credit, which enables you to create complex workflows.
Step 1 — Creating a Free Account on PSPDFKit
Go to our website, where you’ll see the page below, prompting you to create your free account.
Once you’ve created your account, you’ll be welcomed by the page below, which shows an overview of your plan details.
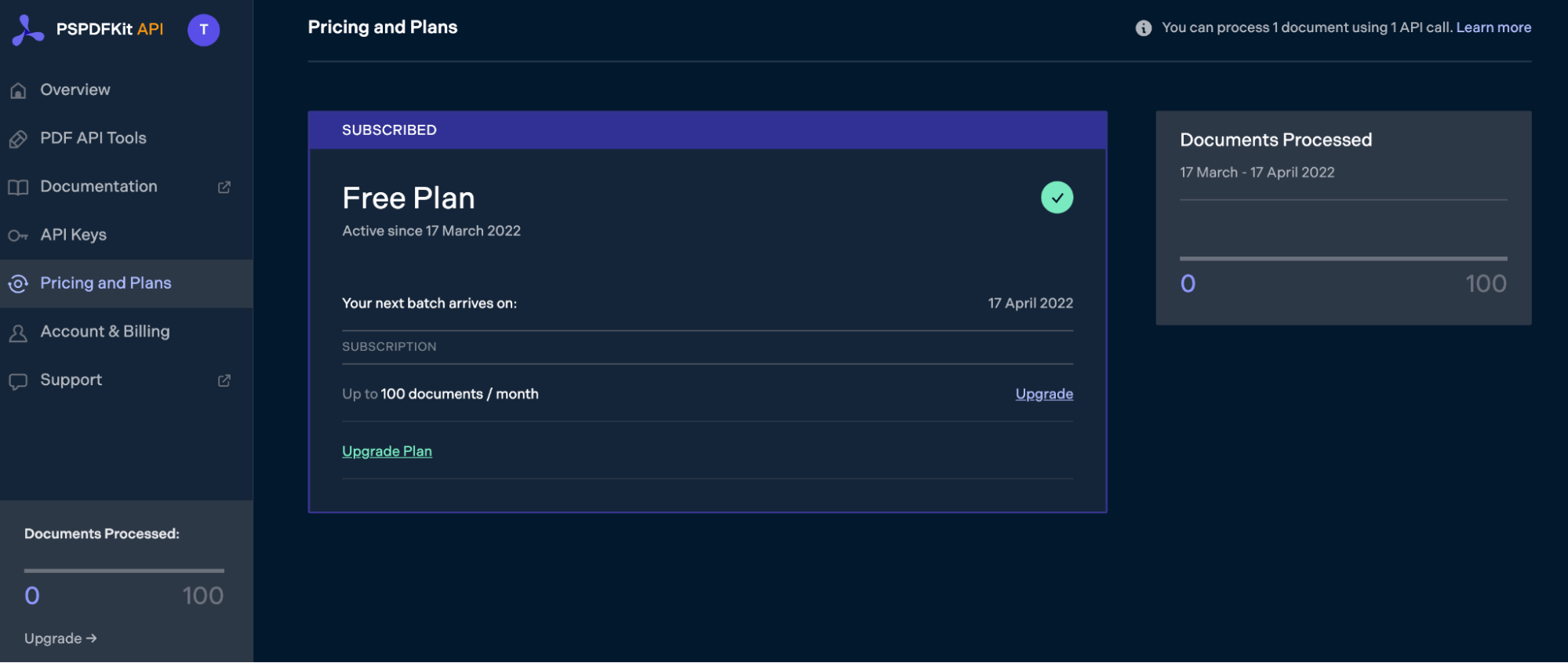
As you can see in the bottom-left corner, you’ll start with 100 documents to process, and you’ll be able to access all our PDF API tools.
Step 2 — Obtaining the API Key
After you’ve verified your email, you can get your API key from the dashboard. In the menu on the left, click API Keys. You’ll see the following page, which is an overview of your keys:
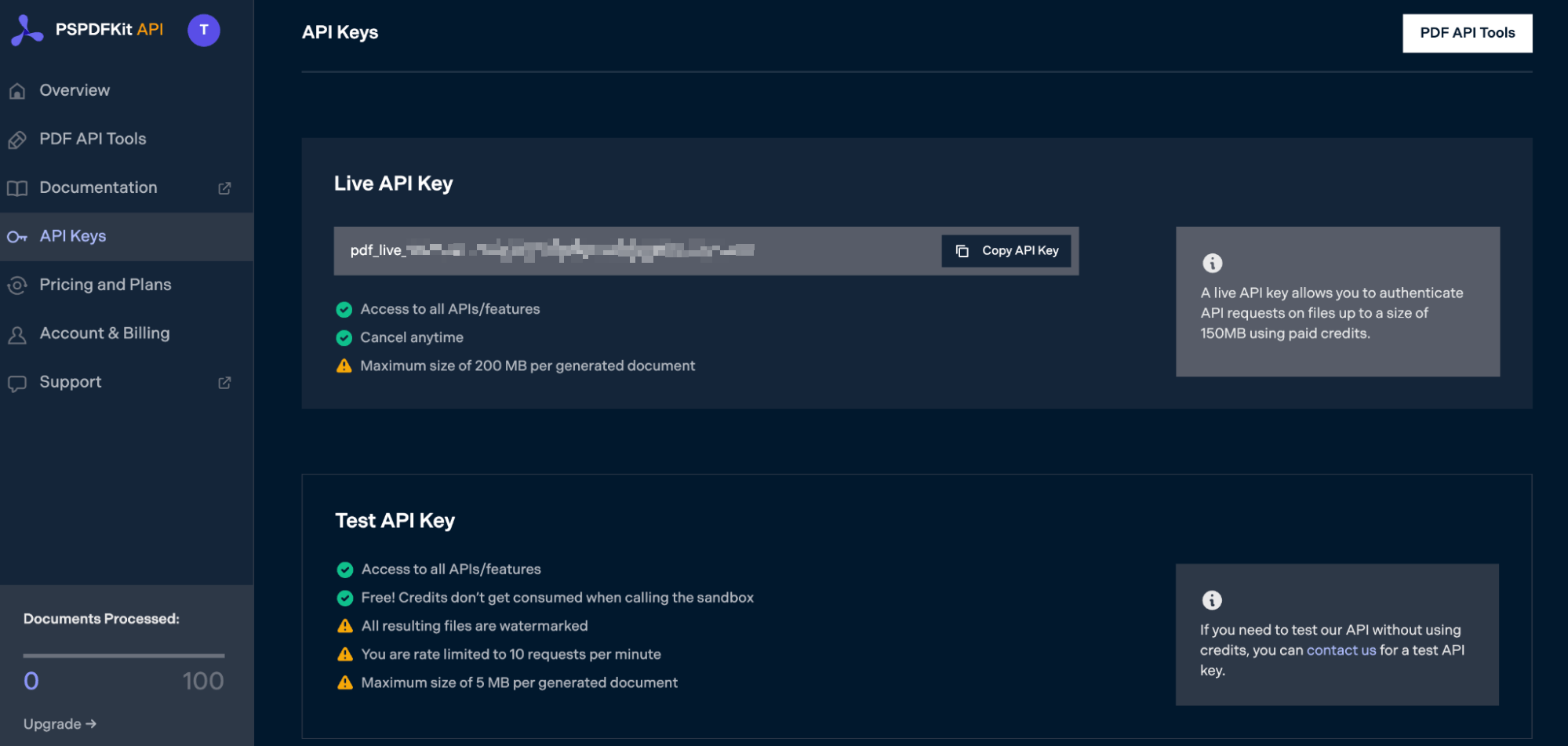
Copy the Live API Key, because you’ll need this for the Flatten PDF API.
Step 3 — Setting Up Folders and Files
Now, create a folder called flatten_pdf and open it in a code editor. For this tutorial, you’ll use VS Code as your primary code editor. Next, create two folders inside flatten_pdf and name them input_documents and processed_documents.
Then, in the root folder, flatten_pdf, create a file called processor.py. This is the file where you’ll keep your code.
Your folder structure will look like this:
flatten_pdf ├── input_documents | └── document.pdf ├── processed_documents └── processor.py
Step 4 — Writing the Code
Assuming you already have Python installed, open the processor.py file in your code editor. Paste the code below into your file:
import requests import json instructions = { 'parts': [ { 'file': 'document' } ], 'actions': [ { 'type': 'flatten' } ] } response = requests.request( 'POST', 'https://api.pspdfkit.com/build', headers = { 'Authorization': 'Bearer YOUR_API_KEY_HERE’ }, files = { 'document': open('input_documents/document.pdf', 'rb') }, data = { 'instructions': json.dumps(instructions) }, stream = True ) if response.ok: with open('processed_documents/result.pdf', 'wb') as fd: for chunk in response.iter_content(chunk_size=8096): fd.write(chunk) else: print(response.text) exit()
ℹ️ Note: Make sure to replace
YOUR_API_KEY_HEREwith your API key.
Code Explanation
In the code above, you first import the requests and json dependencies. After that, you create the instructions for the API call.
You then use the requests module to make the API call, and once it succeeds, you store the result in the processed_documents folder.
Output
To execute the code, use the command below:
python3 processor.py
Once the code has been executed, you’ll see a new processed file, result.pdf, located under the processed_documents folder.
The folder structure will look like this:
flatten_pdf ├── input_documents | └── document.pdf ├── processed_documents | └── result.pdf └── processor.py
Final Words
In this post, you learned how to easily and seamlessly flatten PDF files for your Python application using our Flatten PDF API.
You can integrate these functions into your existing applications and flatten PDFs. With the same API token, you can also perform other operations, such as merging documents into a single PDF, adding watermarks, and more. To get started with a free trial, sign up here.



