Edit Documents in Plain English Using PSPDFKit API and Machine Learning Language Models

Machine learning has many practical applications in the software we use. From recommendation systems, to voice recognition and image processing, there are many kinds of tasks where machine learning algorithms perform very well. Deep learning models, which are a form of machine learning, have opened the door to interesting applications like program generation from English descriptions. In this post, I’ll focus on this particular application and explore how you can train a deep learning model to be able to explain in English what you want to achieve with one of our products, PSPDFKit API.
PSPDFKit API — The Easiest Way to Operate on Documents
If you aren’t familiar with PSPDFKit API, it’s a simple-to-use “pay-as-you-go” service that can perform a lot of operations on PDFs and other document file formats. Operations include splitting and rotating pages, flattening form fields, watermarking, converting to many different file formats, and more. You can read the entire list of operations in our documentation.
PSPDFKit API supports a wide range of technologies — from simple cURL commands, to Java, JavaScript, and C#, among other programming languages. The API is easy to use, but not all people know how to write code. But wouldn’t it be great if you could instead write an English description of what you want to accomplish? For example, a sentence like “Extract the first two pages of document.pdf and generate result.pdf” would produce the correct command or code snippet to accomplish the task using PSPDFKit API. This AI dream is closer than ever thanks to deep learning models for natural language processing tasks, such as OpenAI’s pioneering work on GPT-3. Other language models have extended GPT-3 further with some interesting properties, as we’ll see later.
An Introduction to GPT-3
Generative Pre-trained Transformer 3 (GPT-3) is the third iteration of an autoregressive language model by OpenAI that produces human-like text using deep learning. Since September 2020, Microsoft has had exclusive access to the model. Microsoft created a derivative of GPT-3 named Codex, which is specially trained to generate programs. Codex is the basis of some recent products, like GitHub Copilot, which integrates text editors and IDEs with a service that produces code from natural language descriptions.
Since GPT-3 was introduced, multiple companies have worked on similar autoregressive language models. One of them is Jurassic-1, which we’ll use here to produce commands to use PSPDFKit API with natural language.
Jurassic-1
Jurassic-1 is a language model created by AI21 Labs. It’s similar to GPT-3 in the sense that it consists of an autoregressive model of up to 17 billion parameters that’s trained on a set of English documents. However, it’s different in that in Jurassic-1, the size of the vocabulary and the depth/width ratio of the neural network are larger. This architecture produces significant runtime gains compared to GPT-3: Batch inference is around 7 percent faster, and text generation is up to 23 percent faster. You can read more details about Jurassic-1 in this technical paper.
Training a Jurassic-1 Model to Produce PSPDFKit API Queries
In this example, we’ll train a Jurassic-1 model to generate PSPDFKit API cURL queries from an English description. The website offers a playground where you can test any of the existing models (j1-large, j1-grande, or j1-jumbo). The existing models work well for a wide range of natural language processing tasks, but if your application is specialized — like the use case described in this blog post — you’ll need to train your own model on top of any of the existing ones. To do that, you first need to create a dataset with some training examples.
Datasets in AI21 Studio can be written in two formats: CSV, or JSON Lines. Here, we’ll use CSV, but JSON Lines is probably simpler if you need to quote a lot of strings. The expected CSV format consists of two fields, “prompt,” and “completion.” Prompt is the query in natural language, and completion is what the model should produce. For example, here’s a CSV file with two training examples to generate cURL commands for PSPDFKit API:
prompt,completion
"Curl command to make a PDF result.pdf from HTML file index.html.
","curl -X POST https://api.pspdfkit.com/build \
-H ""Authorization: Bearer your_api_key_here"" \
-o result.pdf \
--fail \
-F index.html=@index.html \
-F instructions='{
""parts"": [
{
""html"": ""index.html""
}
]
}'
"
"Curl command to OCR English PDF document.pdf and generate result.pdf.
","curl -X POST https://api.pspdfkit.com/build \
-H ""Authorization: Bearer your_api_key_here"" \
-o result.pdf \
--fail \
-F scanned=@document.pdf \
-F instructions='{
""parts"": [
{
""file"": ""scanned""
}
],
""actions"": [
{
""type"": ""ocr"",
""language"": ""english""
}
]
}'
"The first prompt is about how to convert PDF files to HTML. The second prompt is about how to perform OCR on a PDF with scanned text in English. Notice that you need to escape string quotes that are part of the cURL command, and that the prompt ends in a newline separator. You can use any existing CSV linter to make sure the format is correct before uploading it to the AI21 Studio web service.
Training Set Requirements
We just showed two training examples, but to produce a high-quality model, we need at least 50 (and the more, the better). The trained model will perform better if there are no duplicates and if most of the training examples have significant differences. For example, it might make sense to add an additional training example where you change the name of the files and/or the output, but a Jurassic-1 model is already “smart” enough to deduce the input file and output file from just one example. In general, it’s better to add examples about a variety of scenarios, like the “export to PDF” vs. “perform OCR on a document” example above.
Uploading and Training the Dataset
Once we have a good CSV or JSON Lines dataset, we need to upload it to the service by clicking Datasets > Upload. If all goes well, this is how the uploaded dataset will look:
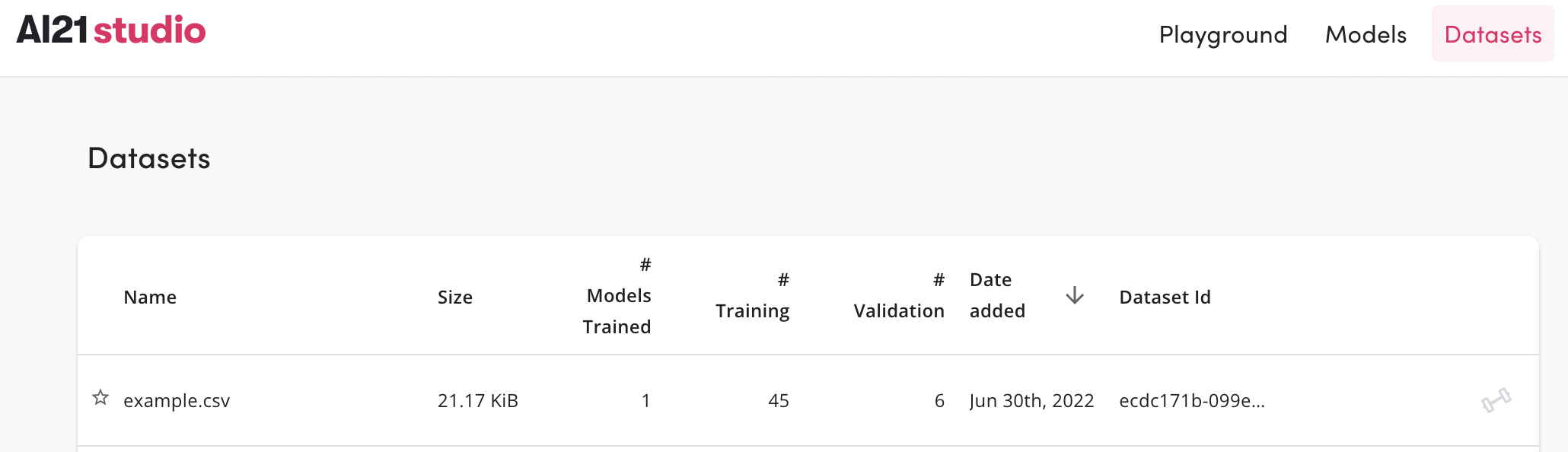
Hover your mouse over the dataset and press the Train icon to train it:
![]()
As you can see in the following screenshot, you can configure the model name, the base model from which to derive the new model (we recommend j1-jumbo for code generation tasks), and parameters like the learning rate or the number of epochs.
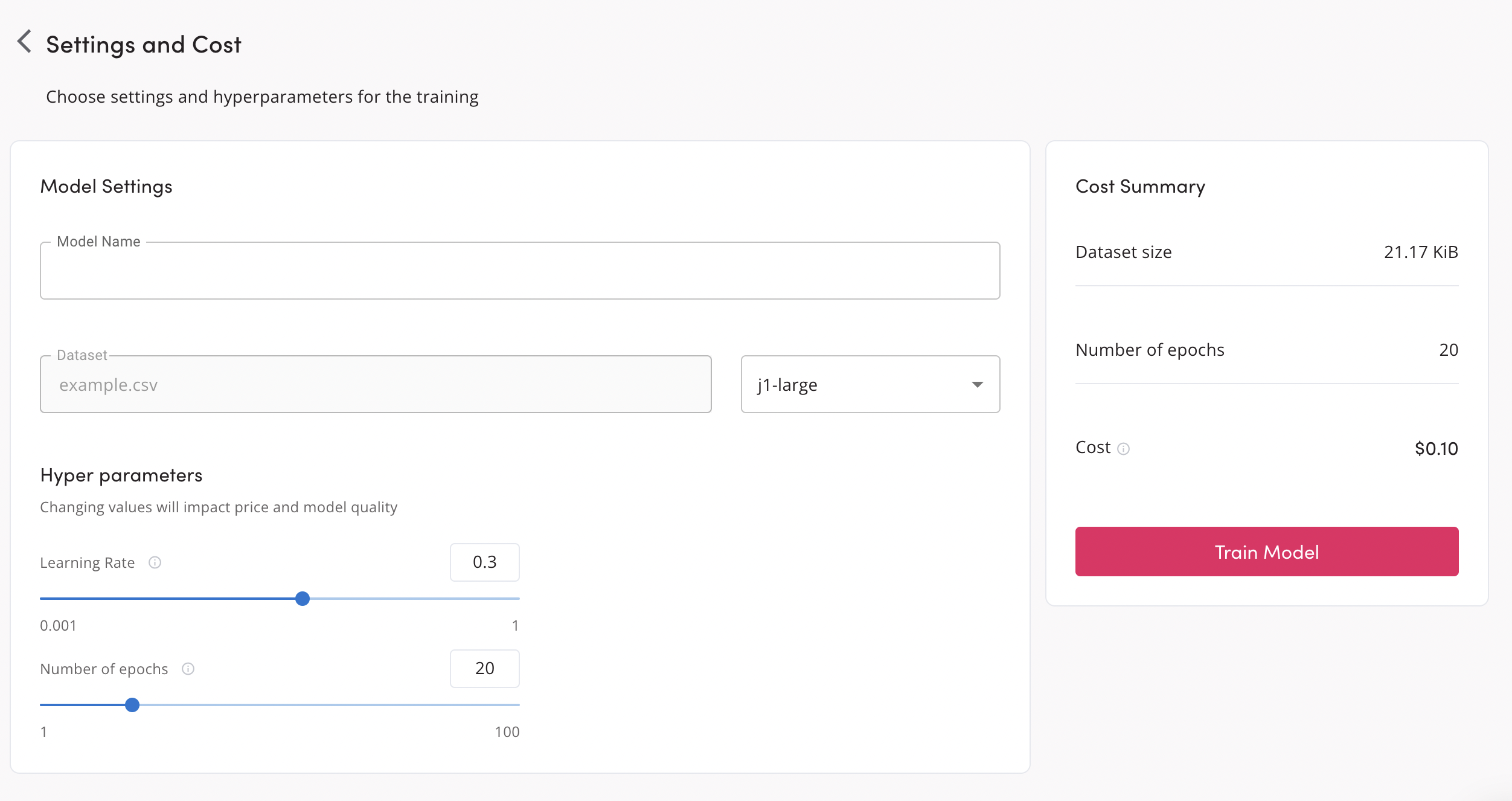
For this use case, we recommend increasing the number of epochs to about 80.
Press Train Model to train the model. Note that, depending on the quality of the model, it may take up to one hour to generate it.
Using the New Trained Model in the Playground
Once the model is trained, if you switch to the Playground tab, you’ll be able to select it from the Model dropdown box:
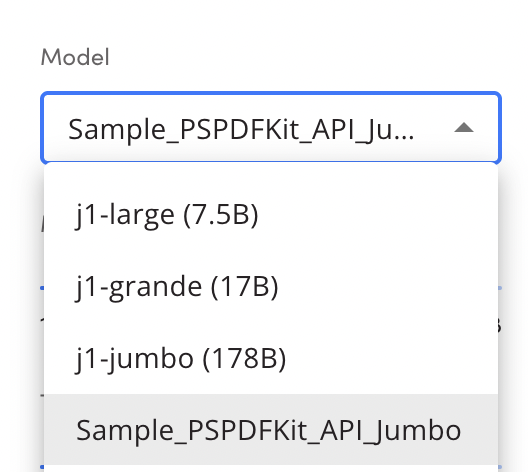
And that’s it. Now you can write text in the playground and press Generate (or Command-Return on Macs, and Control-Enter on other platforms) to generate the corresponding PSPDFKit API cURL command.
Let’s try a simple query like:
“Curl command to flatten document.pdf and generate result.pdf.”
The result is what we’d expect:
curl -X POST https://api.pspdfkit.com/build \ -H "Authorization: Bearer your_api_key_here" \ -o result.pdf \ --fail \ -F document=@document.pdf \ -F instructions='{ "parts": [ { "file": "document" } ], "actions": [ { "type": "flatten" } ] }'
Note that there’s a configurable limit in the maximum completion length. The limit includes the size of prompt and the completion, so for our case, where the cURL commands can be very long, it’s interesting to increase the limit a bit. The maximum is 2,048 tokens, which corresponds to 2,300–2,500 English words.
Now, let’s try another query. We want to extract the last three pages of a PDF using PSPDFKit API:
“Curl command to extract the last 3 pages of document.pdf.”
The result is:
curl -X POST https://api.pspdfkit.com/build \ -H "Authorixzation: Bearer your_api_key_here" \ -o document.pdf \ --fail \ -F document=@document.pdf \ -F instructions='{ "parts": [ { "file": "document", "pages": { "start": -3 } } ] }'
Pretty neat. Now let’s try some document conversion:
“Curl command to convert document.pdf to result.png with DPI of 200.”
The result is accurate, and we didn’t need to read any documentation or learn how to use cURL:
curl -X POST https://api.pspdfkit.com/build \ -H "Authorization: Bearer your_api_key_here" \ -o result.png \ --fail \ -F document=@document.pdf \ -F instructions='{ "parts": [ { "file": "document" } ], "output": { "type": "image", "format": "png", "dpi": 200 } }'
If we find results that aren’t accurate enough, we may want to adapt the dataset or tweak the hyperparameters used when training the model.
Conclusion
At PSPDFKit, we focus on offering all the document processing features your business needs, but we’re also exploring new ways to use our features without writing any code, so as to reduce development costs. In this post, I’ve introduced GPT-3 and related language models, which represent the state of the art in textual and program generation. By training a custom Jurassic-1 model by AI21 Labs, we can generate the PSPDFKit API cURL command for many different document operations from a simple description in English, with no need to write code or read any documentation. PSPDFKit API is designed in a way that makes it a perfect match for GPT-3.
Interested in PSPDFKit API? Just fill our sales form with your business needs and you’ll be processing thousands of documents in no time at all.

Daniel is part of the Core Team at PSPDFKit and has worked on multiple topics, ranging from cryptography and text systems, to file format support and JavaScript engines. Outside of work, he likes spending time with his family, football, reading books, and watching films.