A Peek at Our CD Pipeline
 Reinhard Hafenscher
Reinhard Hafenscher
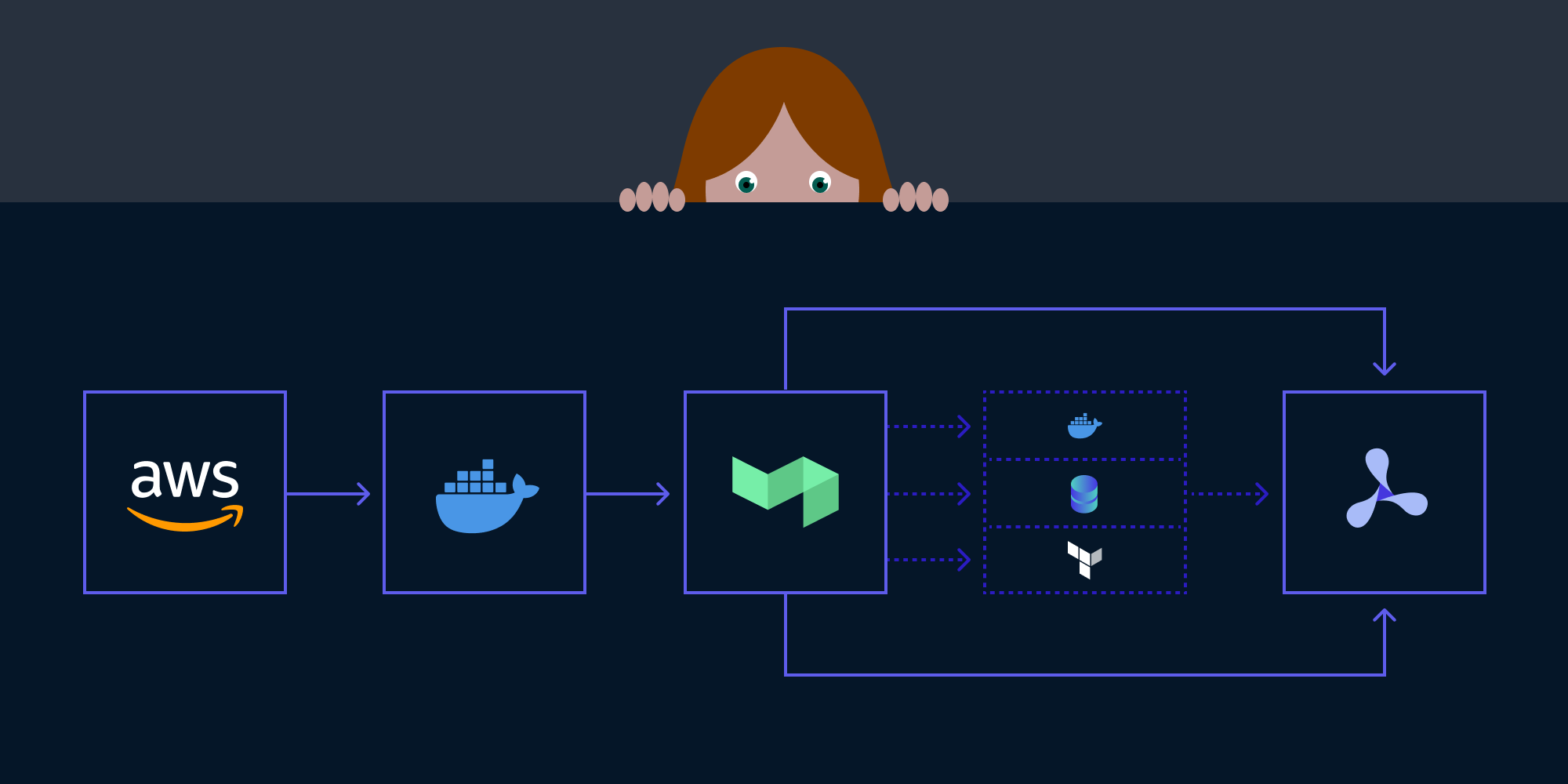
Today I want to give you a peek behind the curtain and walk you through how we set up our continuous deployment (CD) pipeline for PSPDFKit API. More specifically, I’ll talk about which tools we used and how we structured our deployment workflow. So, let’s get started.
Hello World
All our PSPDFKit API infrastructure is hosted on AWS, and the first step in making our CD pipeline work was to choose a tool to define our infrastructure. With AWS, the first choice might be CloudFormation, as it’s an AWS-native way of provisioning the infrastructure. However, since we already had experience managing our CI infrastructure with Terraform, we decided that would be the way to go.
With the tool selected, all we needed to do was set up all the AWS resources required to run. The details of this aren’t relevant to the CD setup itself. What matters is that by using Terraform, we can check if a pull request changes any part of our deployed infrastructure, and if so, we can apply the changes automatically.
Shipping Containers
Infrastructure is one half of the equation, and the other half is deploying is our actual code. For PSPDFKit API, we make use of ECS, which means we have to build Docker images. Luckily for us, this is something we have a lot of experience with, since PSPDFKit Server and PSPDFKit Processor are shipped as Docker images.
There isn’t any magic here; we just have a Dockerfile for each of our services that installs the dependencies needed, builds the code, and sets up the entry point.
For our CD pipeline, all we need to do is wrap each process in a job we can run on CI and then upload the resulting image to our registry. Then, when our ECS tasks start, they pull the latest image from the registry. One thing to note here is that PSPDFKit API is actually composed of multiple different services working together — something we can make use of later to improve the turnaround time of our CD pipeline.
Putting It Together
Now this is where it gets interesting. We use Buildkite for our CI, so the final step is to put things together in a way that makes sense. One of the powerful things about Buildkite is that you can dynamically generate your pipeline on demand. For this, we have a Ruby script, and we use it to do the following:
-
First, we check if there were any changes to our infrastructure by running
terraform plan. When runningplan, Terraform will detect all changes between the deployed infrastructure and the infrastructure defined locally. In our case, this encompasses both actual infrastructure changes and changes to the Docker image used (since we tag each image with the Git SHA we built it from, causing it to be marked as a change). For this reason, we explicitly first try runningterraform planwith the currently deployed image tag to determine if there are infrastructure changes or only code changes. -
Next, we check if any of our services needs to be updated. We do this by generating a Git diff of the commit being deployed (in our case, the latest master merge) and the last successfully deployed commit. Then, we check if any of the changed files are part of any of our deployed services. Since we have a monorepo, this is needed to filter out unrelated changes and prevent useless deployments from running.
-
Finally, once we’ve determined what parts of the pipeline need to run, we can assemble it.
This is run for every merge to master. We also make use of concurrency groups to ensure that all merges to master are deployed in order, and that only one job is touching our infrastructure at any one time.
The Final Pipeline
Here’s how the final pipeline looks, including all the steps that can optionally be skipped:
-
If there are code changes, we build our services. Here, we take advantage of the fact that we split PSPDFKit API into multiple smaller services. This allows us to only build and deploy the services that actually changed, in turn speeding up the deployment.
-
This step not only builds a release-ready Docker image, but it also runs the full test suite to prevent concurrent merges from introducing errors on master.
-
It also pushes our built images to our internal Docker registry tagged with the current Git SHA.
-
We run two full deployments of PSPDFKit API: a staging one and a production one. Our CD pipeline always runs for the staging deployment first, and then, if there are no errors, for the production deployment.
-
If we’re in production and we find infrastructure changes, we require a manual unblock step before deployment. Otherwise, the whole pipeline runs automatically.
-
Once we’re ready to run, we update our deployed infrastructure. This also updates our ECS task used for database (DB) migrations.
-
Then, we run any DB migrations that have been introduced since the last successful deployment. Part of this also entails enabling and disabling feature flags, which allows us to merge and test features on staging without affecting production.
-
Finally, we deploy the latest version of our services that we built in the first step.
Here are the concrete steps we took to make this fast:
-
Only deploy what you need. We spent a lot of time ensuring that our deployment pipeline skips all steps that aren’t needed.
-
Keep tests fast. We recently wrote about the benefits of keeping CI fast, and the same idea applies here. Making your test suite fast for PRs also makes your deployment fast.
-
Skip steps that don’t matter. While each PR needs to make sure the committed code is formatted and passes the linter and any other static checks, these steps aren’t needed in the deployment pipeline, and skipping them can shave off valuable seconds.
-
Use the right tools. Terraform is incredibly fast at both checking if there are changes and applying them, often taking less than a minute to do this with our entire infrastructure.
Conclusion
While this only scraped the surface of our setup, I hope it still serves as useful inspiration for determining what can be done and where you have the potential for optimization. Ultimately, a continuous deployment pipeline is a unique as the product it’s built for, and there’s no one-size-fits-all approach, but the general ideas still apply.



