The Perils of Large Files in Elixir


Last September, I had the opportunity to give a talk at ElixirConf.eu. This talk, entitled “The Perils of Large Files,” was a summary of our learnings working with large files on PSPDFKit Server and PSPDFKit Processor. This blog post is an adaptation of the talk’s contents, and its principles can be applied to any application written in Elixir and Erlang/OTP.
The Problem Space
PDF files can range dramatically in size — from a small, 30 KB contract, to a 1 GB illustrated book, and more. Dealing with large files requires extra care. If mishandled, a single large file can quickly exhaust available resources, in turn causing:
-
Memory exhaustion — Operating on two to three files causes the entire application to run out of memory.
-
Memory leaks — After operating on a specific file, the system memory doesn’t return to the levels it was at before the start of the file operation itself.
-
IO starvation — The amount of read/write operations on files causes the application to struggle executing any other task, e.g. reading information from a database or writing temporary files.
-
CPU starvation — Calculations on files exhaust CPU capacity, leading to the failure of completely unrelated application components.
In other words, availability is directly related to the way we manipulate large files.
In this blog post, we’ll focus primarily on memory-related issues.
Use Cases
To understand how to work with large files, we’ll explore three use cases:
-
Reading files in a cache store
-
Calculating the SHA-256 checksum of a given file
-
Fetching a large file from a remote source (e.g. an HTTP server) and writing it to disk
For each use case, we’ll analyze an initial implementation, perform some measurements, and outline some mitigation strategies. The objective is not to offer one-size-fits-all solutions, but to show a methodical approach that can be used in similar situations.
Reading Files in a Cache Store
A common scenario with large files is a file system cache store: Given a parent directory, we want to mediate access to the files contained within. In this example, we’ll focus on reading files out of the cache store.
We can use a GenServer to model the cache store:
-
The process is started with a base path (the directory containing files), which is kept in the process state.
-
The process exposes a synchronous API (
read/1) to read a file’s contents given its relative path.
Here’s a minimal implementation:
defmodule Perils.Examples.Cache do use GenServer def start_link(base_path) do GenServer.start_link(__MODULE__, base_path, name: __MODULE__) end def init(base_path) do {:ok, base_path} end def read(file_name) do GenServer.call(__MODULE__, {:read, file_name}) end def handle_call({:read, file_name}, _from, base_path) do full_path = Path.join(base_path, file_name) contents = File.read!(full_path) {:reply, contents, base_path} end end
The design of this implementation isn’t optimal, as it imposes sequential access to files in the directory, but it’s a perfect example of what can go wrong when reading files from disk.
Let’s measure memory use when working with this cache store implementation: We’re going to use some built-in tools available in the Elixir and Erlang standard libraries, along with Recon, a package by Fred Hebert that provides a wide range of troubleshooting tools.
Our test will:
-
Check the initial total memory
-
Read a 128 MB file
-
Check the total memory again
:erlang.memory(:total) |> IO.inspect(label: "Total before read") Perils.Examples.Cache.read("large.dat") :erlang.memory(:total) |> IO.inspect(label: "Total after read")
Total before read: 31581496 Total after read: 166084696
Results are expressed in bytes and show that after reading the file, our memory use grew roughly the same amount as the file size. The BEAM runtime uses a reference count mechanism for binary data larger than 64 bytes, so this delta implies that one or more processes are holding a reference to the contents of the file.
One could assume that as the test process reads the file contents, it’s the one holding a reference, but it’s always better to gather hard data.
We can update our test code to use :recon.bin_leak/1, which measures memory usage, triggers garbage collection, and returns a report that processes that released memory.
We’ll run :recon.bin_leak/1, reporting 10 processes that released memory (in descending order in respect to the number of references dropped). The Enum.filter/2 call will remove all processes different from our cache store from the result:
:erlang.memory(:total) |> IO.inspect(label: "Total before read") Perils.Examples.Cache.read("large.dat") :erlang.memory(:total) |> IO.inspect(label: "Total after read") :recon.bin_leak(10) |> Enum.filter(fn {_pid, _delta, [m, _f, _a]} -> m == Perils.Examples.Cache _other -> false end) |> IO.inspect(label: "GC delta") :erlang.memory(:total) |> IO.inspect(label: "Total after GC")
Rerunning the test, we obtain confirmation that our cache store held two references that were garbage collected:
Total before read: 31581496 Total after read: 166084696 GC delta: [ {#PID<0.174.0>, -2, [ Perils.Examples.Cache, {:current_function, {:gen_server, :loop, 7}}, {:initial_call, {:proc_lib, :init_p, 5}} ]} ] Total after GC: 30268152
These results may be a bit surprising at first, but there’s a valid explanation: Our cache store is under very little load, so it doesn’t trigger automatic garbage collection. This behavior can be observed in many applications that don’t have much traffic; while numbers may vary, in my experience, processes that receive a read request every two to three seconds can suffer from this problem.
There are different ways to mitigate this issue, the simplest one being changing the return value of handle_call/3 from {:reply, contents, base_path} to {:reply, contents, base_path, :hibernate}. By instructing the process to hibernate, the runtime triggers a garbage collection and releases all unneeded references. Hibernation comes at a (tiny) CPU cost when “waking up” the process (which happens automatically when it receives a new request).
A different approach could be to revise the cache store API: Instead of returning file contents, it could return the path of the file. Once the caller process has the path of the file, they can decide how to best interact with it. Note that this approach may lead to race conditions: What if the cache store deletes the file before the caller process can read it?
Calculating the SHA-256 of a File
Given a file path, we want to calculate the SHA-256 of its contents for verification purposes.
We can use the :crypto library included with Erlang/OTP:
defmodule Perils.Examples.Sha do def sha256(file_name) do contents = File.read!(file_name) :sha256 |> :crypto.hash(contents) |> Base.encode32(case: :lower, padding: false) end end
Our implementation reads the file, hashes its contents, and then encodes the resulting SHA in Base32 so that it’s human readable and usable in data stores and URLs.
We can test resource usage of this function by:
-
Checking the initial total memory
-
Calculating the SHA of a 128 MB file
-
Checking total memory after hashing
-
Using
:recon.bin_leak/1to trigger a GC -
Checking total memory after GC
:erlang.memory(:total) |> IO.inspect(label: "Total before sha") "large.dat" |> Perils.Examples.Sha.sha256() |> IO.inspect(label: "File sha") :erlang.memory(:total) |> IO.inspect(label: "Total after sha") :recon.bin_leak(10) :erlang.memory(:total) |> IO.inspect(label: "Total after GC")
The results show a memory jump roughly the same size of the file:
Total before sha: 31639536 File sha: "evf4yp6e6jyxey3n6s7tfxu7cb7wedkvtmqnoyazpzcsxf2fhelq" Total after sha: 166487096 Total after GC: 30668392
We can also see that garbage collection reclaims memory used, as we’d expect. As long as we perform hashing in a shortlived process, we don’t have to worry about memory leaks.
The issue in this implementation is around peak memory usage: The size of the file determines the total memory used. If we have 4 files that are 500 MB each, we’d need 2 GB of memory to hash them in parallel. For the test file, we can look at the memory profile inside the Observer application.
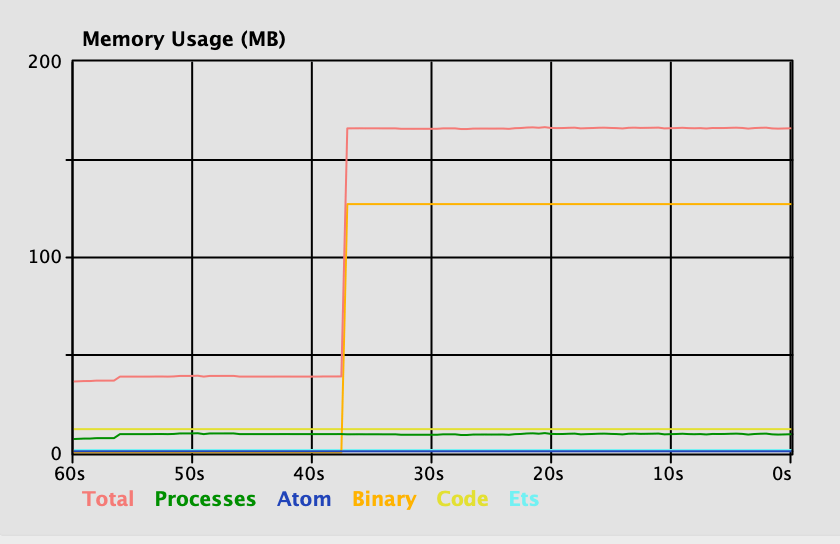
Memory rises sharply when calculating the SHA, and it’s retained until garbage collection.
We can improve peak memory usage by streaming the file instead of reading it all at once:
defmodule Perils.Examples.Sha do def sha256(file_name) do line_or_bytes = 8_000_000 # 8MB stream = File.stream!(file_name, [], line_or_bytes) initial_digest = :crypto.hash_init(:sha256) stream |> Enum.reduce(initial_digest, fn chunk, digest -> :crypto.hash_update(digest, chunk) end) |> :crypto.hash_final() |> Base.encode32(case: :lower, padding: false) end end
In the updated example code, we set up a File.stream!/3 at the specified path, which will lazily read 8 MB chunks at a time. We initialize a SHA-256 digest and then start consuming the file stream: For each chunk read, we update the digest. Once the stream finishes, we finalize the hash and encode it to Base32.
The performance profile for this version of the function is radically different:
Total before sha: 31361384 File sha: "evf4yp6e6jyxey3n6s7tfxu7cb7wedkvtmqnoyazpzcsxf2fhelq" Total after sha: 32296312 Total after GC: 30696640
We can see that, at most, we occupy around 8 MB, which is the maximum size of each file chunk. Looking at the observer graph, we can see a small spike and comparable execution times compared to the inefficient version.
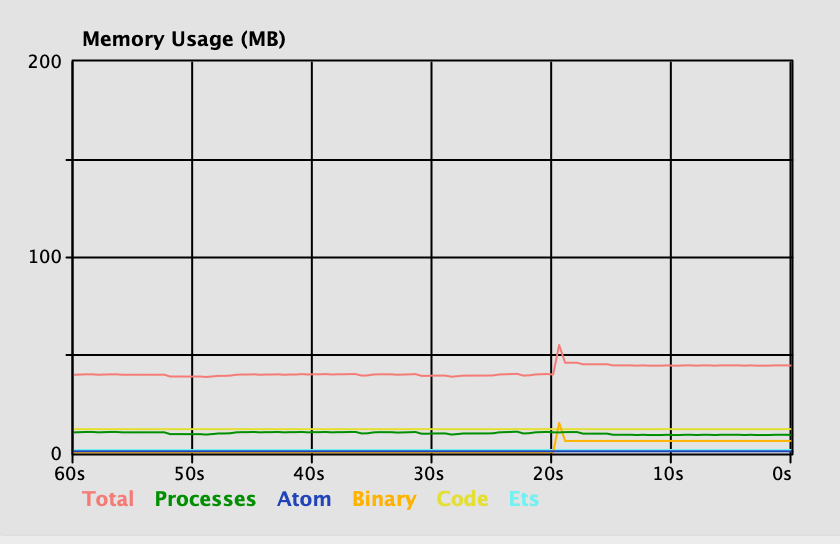
With this implementation, we improve our ability to produce hashes in parallel, which means we can do more with the same amount of total memory. It’s important to remember that as we can do more work, we’re likely to use more IO and CPU.
Fetching a Large File from a Remote Source
For this use case, we want to fetch a file from a remote HTTP endpoint and write it to a specified local file. There are several HTTP clients available in the Elixir ecosystem, but for this example, we’ll use :httpc, as it’s part of the Erlang/OTP standard library:
defmodule Perils.Examples.Store do def write(file_name, url) do with {:ok, data} <- get(url) do File.write!(file_name, data) end end defp get(url) do :httpc.request(:get, {String.to_charlist(url), []}, [], body_format: :binary) |> case do {:ok, result} -> {{_, 200, _}, _headers, body} = result {:ok, body} error -> error end end end
In the example code, we fetch a file from a URL, get the response body, and write it to a specified path. For the sake of keeping the example focused, we won’t do any error handling.
We can test this code using a file from one of our examples, a 12 MB PDF document:
url = "https://pspdfkit.com/demo/magazine-viewer" # 12MB Perils.Examples.Store.write("magazine.pdf", url)
Execution time is effectively bound to the network speed, but if we look at memory usage via the Observer, we see a spike:
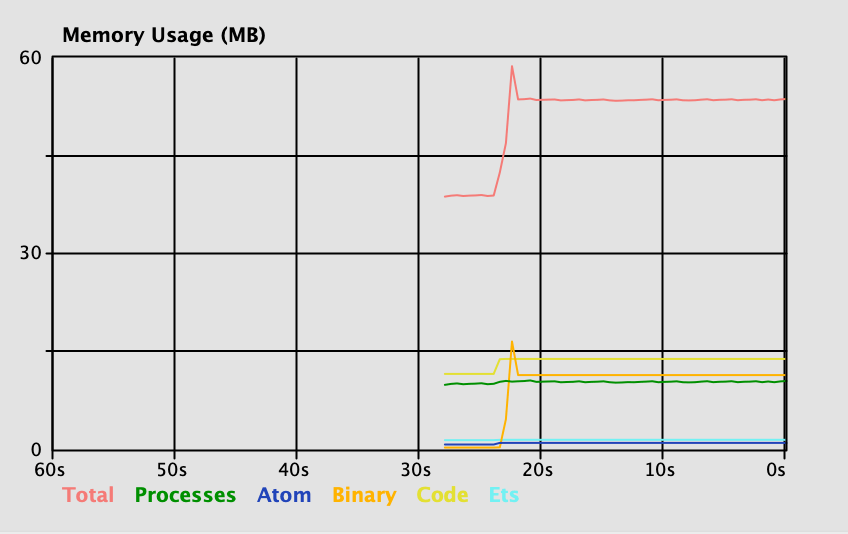
The memory usage delta maps roughly to the file size, plus some overhead most likely connected to handling the HTTP request. We can infer from this behavior that with this implementation, the ability to concurrently process multiple operations is directly related to the size of the file to fetch.
We can improve the implementation and achieve more deterministic memory use by streaming and writing the file without ever loading its entire contents in memory. While :httpc provides an option to stream directly to a specified path, it’s worth showing a more generic, message passing-based technique that can be used with a wider range of libraries.
We’ll start by instructing :httpc.request/4 to operate in asynchronous mode, sending response chunks to the calling process:
def stream_write(file_name, url) do {:ok, ref} = :httpc.request(:get, {String.to_charlist(url), []}, [], stream: :self, sync: false) stream_loop(ref, file_name) end
We can then start processing response chunks in a loop:
defp stream_loop(ref, file_name) do receive do {:http, {^ref, :stream_start, _headers}} -> file = File.open!(file_name, [:write, :raw]) write_loop(ref, file) after 5000 -> {:error, :timeout} end end defp write_loop(ref, file) do receive do {:http, {^ref, :stream, chunk}} -> IO.binwrite(file, chunk) write_loop(ref, file) {:http, {^ref, :stream_end, _headers}} -> File.close(file) after 5000 -> File.close(file) {:error, :timeout} end end
Loops are structured so that:
-
In
stream_loop/2, we initially wait for a:stream_startresponse to the request and open the local file path for writing (we’ll explain later on why we’re using the:rawoption). -
Once we have the file open, we start the write loop defined at
write_loop/2. -
Inside
write_loop/2, we wait for stream chunks. Every time we receive one, we append it to the file and recursively callwrite_loop/2again. -
When we receive
:stream_end, we know the response has finished and we can close the file. -
If at any point inside
write_loop/2we don’t receive a message for more than 5,000 milliseconds, we close the file and return an error.
This implementation has a larger number of moving parts, but its performance profile is radically better.
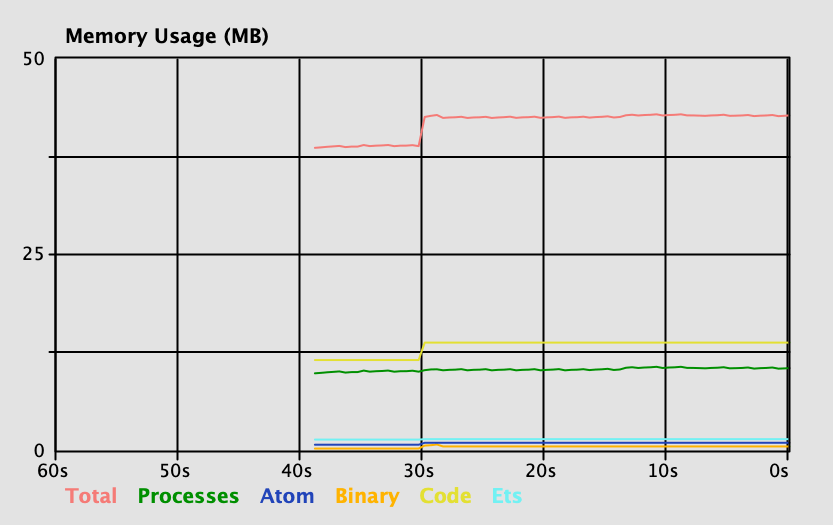
There are, however, some sharp corners we need to be mindful about.
We open the file with :raw mode. This option bypasses the intermediary file server that would otherwise be used to mediate access to the file, giving direct access to the IO device for the open file. By choosing to use :raw mode, we improve performance and concurrency, as access to the file doesn’t need to be serialized via the unique file server process.
We do, however, give up two guarantees:
-
The file reference returned by
File.open/2can only be used in the same Elixir/Erlang node, so the entire file operation has to be completed in the same node. -
The process that opens the file isn’t monitored; if the process terminates, the file isn’t automatically closed. This is why we take extra care and manually call
File.close/1twice.
General Recommendations and References
There’s no silver bullet in software engineering, and the same goes for large file management, but we can extract some recommendations and provide some references:
-
Collect metrics around file operations, both as individual benchmarks and aggregate metrics. Benchmarks help improve the program logic, while aggregated metrics help you plan capacity and inform limits of the infrastructure you’re running. We recommend looking at telemetry and related packages to instrument your application.
-
Control the amount of processes that can use system resources, preferring, where possible, shortlived processes instead of long-running pools. For some ideas on architectural patterns, you can look at duomark/epocxy.
-
For a primer on operating Elixir and Erlang applications in production, you can read “Stuff Goes Bad: Erlang in Anger,” a free and very practical book by Fred Hebert that will guide you through the most common pitfalls of running BEAM applications in production.
-
Use Recon and read its docs, as it provides insight on all sorts of issues.
-
Perform load testing, with particular emphasis on soak testing, as it tends to surface memory and file leaks.
These recommendations are fairly broad and can be used for use cases other than large files. I hope you’ll find a way to use them in your project.