How a B-Tree Helped Reduce Memory Usage in Our Framework
Data structures and algorithms are the core of any non-trivial program. Choosing the right data structure or algorithm can have a notable impact on the performance of a program by making computers solve problems with less work. In this article, I’ll present some suggestions of how to approach performance problems in software and share an example of how we reduced memory usage in our SDK by replacing a data structure with another one called a B-tree.
How to Identify Performance Problems in an Application
When there seems to be a performance problem in an application, it’s important to disprove the null hypothesis, which states that there’s no performance problem at all. That is, you need to be really sure there’s a performance problem before trying to fix it. The best way to disprove the null hypothesis in this case is to use a specialized tool to monitor and profile the application. There are many of them — for example, on macOS you can use Instruments, and on a Linux system you can use perf.
Below are a few general suggestions for identifying and fixing performance problems using a profiler.
Focus on CPU and Memory Hotspots
When you profile the CPU or memory usage of an application, you’ll definitely see the parts of the code that are contributing the most to the perceived slowness. That slowness can happen because those parts of the code are executed a lot of times, or because they’re extremely slow or memory inefficient.
Try to Remove the Hotspot Completely, but Consider the Tradeoffs
Once you’ve identified a particular hotspot in your application, instead of trying to micro-optimize it (which may yield small performance gains while increasing the complexity of the code), first try to remove it completely. Ask yourself if that piece of code is really needed by identifying the problem it’s solving and determining if it still needs to be solved or if it can be solved in a more efficient way. Use your data structures and algorithms knowledge to try to come up with a better way to solve the problem. As this research article shows, solving problems by removing existing things instead of adding new ones is a less obvious solution, but it’s worth the effort.
Note that in most cases, there isn’t an absolute “better” way to solve a problem, so your solution will probably have tradeoffs, e.g. it consumes less memory, but it’s a bit slower. Or, it may use algorithms that are slower in theory, but that exploit cache locality better in practice.
Implement the Code Change and Measure Again
Once you have a plan, implement the code changes and measure again to see if the performance problem has actually improved. If it has, then you might find a different hotspot. Repeat the same process again until you’re happy with the performance of the application.
The following section will give a practical example of a performance improvement we implemented recently, where changing a data structure reduced memory usage significantly without affecting performance.
The Case of a PDF Cross-Reference Table That Used a Lot of Memory
Some time ago, we received a report that a PDF consumed a significant amount of memory. The PDF file in question was very big: It contained thousands of pages and a huge table of contents.
We focused on checking if there was any performance hotspot, and we found one when our software loaded the PDF cross-reference table. What is a cross-reference table, you may ask? It’s the part of a PDF that works like the index of a book and allows PDF software to quickly search and load a specific part of the PDF without needing to scan the whole file sequentially. In this blog post, we explain how it works in more detail. The PDF file in question had a cross-reference table with millions of entries, which, when loaded, consumed a lot of memory.
Digging into the memory usage pattern a bit more showed that each element in the cross-reference table consumed around 40 bytes of memory. That seems high compared to the amount of memory required to store an integer, and a cross-reference table basically contains integers that represent PDF objects and their position in the file. We thought we could do better. Our cross-reference table was implemented using a standard ordered map, which is implemented in terms of a data structure known as a red-black tree. In the next section, I’ll briefly explain how red-black trees work so you can better understand the reasons for the memory overhead we saw.
What Is a Red-Black Tree?
The standard libraries of many programming languages implement dictionaries by using a red-black tree. A red-black tree is a type of tree data structure where nodes contain at least one pointer to each of their children, optional pointers to their parents, and an additional bit that says if the node is colored red or black (this is used when the tree modification algorithm needs to balance the tree). The following picture depicts a red-black tree with 10 numbers:
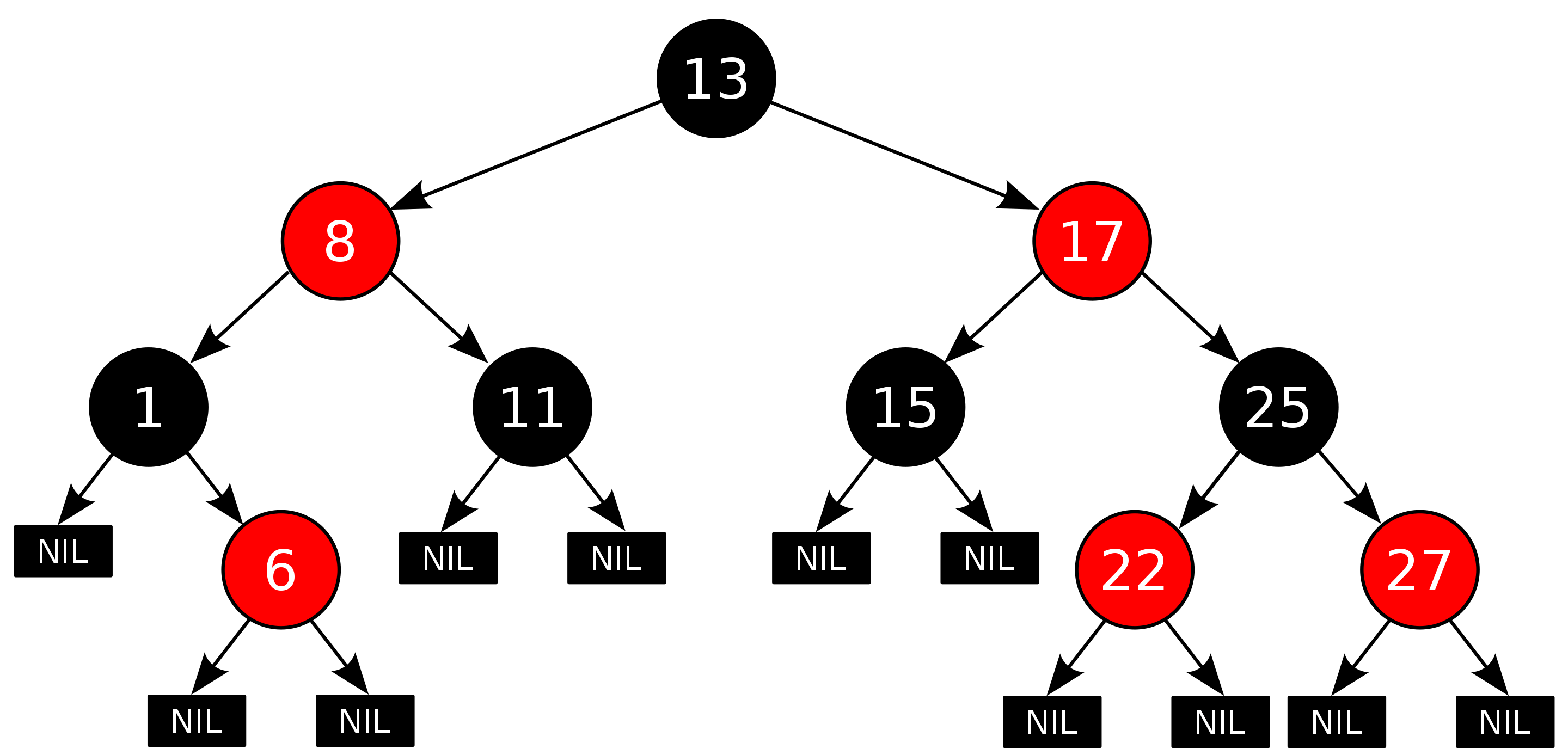 From https://en.wikipedia.org/wiki/Red–black_tree
From https://en.wikipedia.org/wiki/Red–black_tree
Given that a pointer requires 8 bytes in a typical architecture today, the pointers in the tree can easily represent an overhead of around 20–30 bytes per tree node. As we stored millions of objects in a red-black tree for that particular document, the overhead was noteworthy.
When thinking about how to improve the situation, we acknowledged that there are multiple ways to implement a dictionary in a computer, and some are better than others depending on the context. For example, for searching on disk and not the main memory, databases have traditionally used a special tree data structure known as a B-tree. B-trees are getting more popular nowadays among standard library writers as a way of implementing a dictionary in modern architectures where fast cache access is important; this is because B-trees use the cache very efficiently. The next section will provide a description of what a B-tree is and how it can have a smaller memory footprint than a red-black tree in some cases.
What Is a B-Tree and How Can It Be an Improvement over a Red-Black Tree?
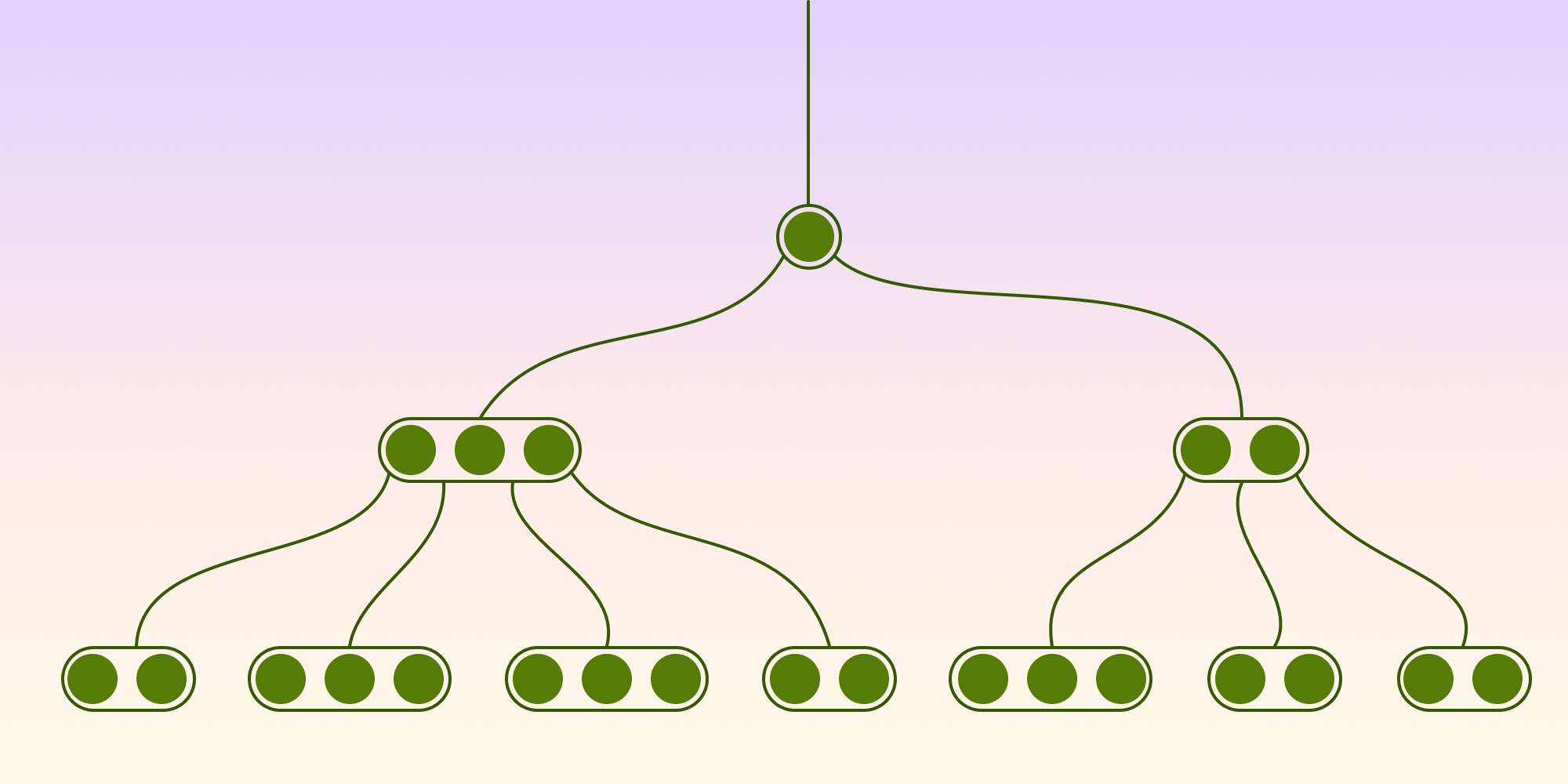
A B-tree is a tree where nodes are grouped into pages. As you can see in the picture below, instead of storing nodes individually, a B-tree stores them in an array (page):
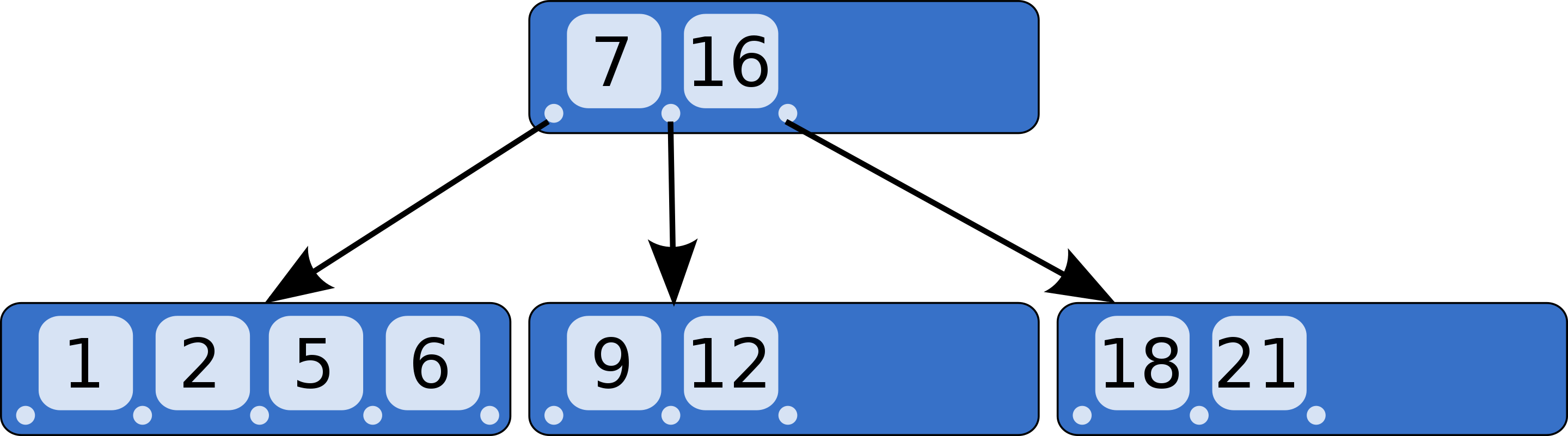 From https://en.wikipedia.org/wiki/B-tree
From https://en.wikipedia.org/wiki/B-tree
If we access one page a time, we reduce the number of searches needed to find any element in the dictionary. Moreover, the page can be kept in the cache so that queries for adjacent elements can take less time. Another important aspect of a B-tree is that it reduces the number of pointers per node compared to a red-black tree.
A search in a B-tree has a similar time complexity to a search in a red-black tree. If you store N elements in a red-black tree, a search for any element will take time proportional to O(nlogn). A search will take the same time with a B-tree, provided that you search inside each page using binary search. Even searching linearly inside each page may not be a bad idea, because a linear search exploits cache locality better than a binary search.
Insertion in a B-tree may take more time compared to a red-black tree, because when a page is full, we need to split it in two and copy the elements in it. Fortunately, for our use case, which is representing the cross-reference table in a PDF, modifications are less common than queries.
Even with these attractive characteristics of a B-tree, you always need to measure how the implementation performs in practice. After we changed our implementation from a red-black tree to a B-tree, we didn’t observe any performance gains or losses, but memory usage decreased by a range of 5–33 percent, depending on the number of PDF objects in the document. The larger the number of PDF objects, the greater the improvement we saw.
Improving Our PDFium Implementation
Once we decided that a B-tree was a better data structure for our use cases, we proceeded to change our PDF engine. As we described in an earlier blog post, our PDF engine uses a heavily modified version of the PDFium library. This particular memory usage improvement is just another example of the multiple additions and bug fixes we’ve made to the PDFium project over time to ensure it excels at loading and rendering PDF documents.
Conclusion
In this blog post, I offered some suggestions to approach software performance problems and explained how thinking in terms of data structures and algorithms can have a great impact on how a program performs or uses memory. Coming up with better algorithms is one way to make faster software in an era where CPU clocks are no longer getting faster.
In this case, we found changing the representation of the PDF cross-reference table from a red-black tree to a B-tree reduced memory usage between 5–33 percent without any impact on existing performance. At PSPDFKit, we consider software performance a very important aspect, so we’ll continue to improve it as much as we can so that you can work with big documents efficiently.

Daniel is part of the Core Team at PSPDFKit and has worked on multiple topics, ranging from cryptography and text systems, to file format support and JavaScript engines. Outside of work, he likes spending time with his family, football, reading books, and watching films.