PDF Syntax 101

In this article, we’ll cover some aspects of how a PDF is structured internally and provide an overview of some of the building blocks the file format consists of.
Everything about the structure of a PDF is covered in the PDF Specification, although sometimes the PDF spec might be a bit vague, or the actual behavior, even in Adobe’s products, might differ slightly in the actual implementation. So when parsing a PDF, you’ll need to adjust for some edge cases and parse some things loosely, so as to not strictly reject everything that varies from the spec.
Since PSPDFKit already handles parsing and interpreting PDF files, even in the weirdest of edge cases, you don’t have to manually handle PDFs. But if you’re still interested in how a PDF looks under the hood and how the visual page representations are created, (be my guest and) read on.
File Structure
This is what a simple PDF with one page and the text “Hello PSPDFKit” looks like when shown in raw text:
%PDF-1.7 1 0 obj << /Type /Catalog /Pages 2 0 R >> endobj 2 0 obj << /Type /Pages /Kids [ 3 0 R ] /Count 1 >> endobj 3 0 obj << /Type /Page /Parent 2 0 R /MediaBox [ 0 0 595 842 ] /Resources 4 0 R /Contents 5 0 R >> endobj 4 0 obj << /ProcSet[ /PDF /Text ] /Font <</Font1 << /Type /Font /Subtype /TrueType /BaseFont /Helvetica >> >> >> endobj 5 0 obj << /Length 55 >> stream BT /Font1 35 Tf 1 0 0 1 170 450 Tm (Hello PSPDFKit) Tj ET endstream endobj xref 0 6 0000000000 65535 f 0000000009 00000 n 0000000062 00000 n 0000000125 00000 n 0000000239 00000 n 0000000343 00000 n trailer << /Root 1 0 R /Size 14 >> startxref 382 %%EOF
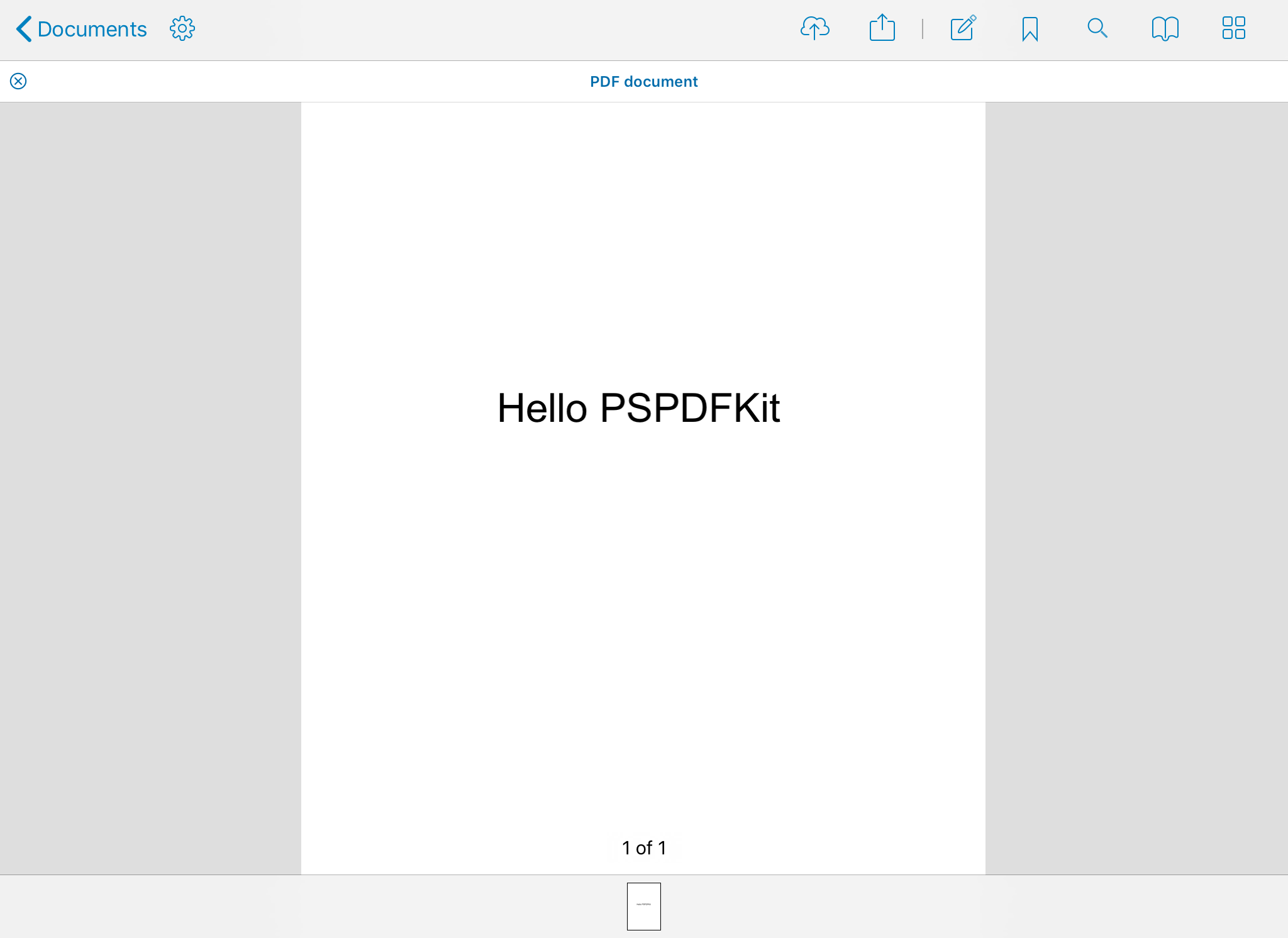
While this example might look like PDFs are text-based documents, this impression is false, since PDFs are binary documents.
PDF Objects
A PDF consists of so-called objects that can have varying types, like null, Boolean, integer, real, name, string, array, dictionary, and stream.
These objects can be referenced either directly or indirectly in the file. Direct objects are placed inline where they are used, while indirect objects are referenced and placed somewhere else inside the document.
Direct Object Reference
Direct objects are constructed inline, directly in the place where they are used.
This snippet shows how to use a font as a direct object:
<< /ProcSet[ /PDF /Text ] /Font <</Font1<</BaseFont/Helvetica/Subtype/TrueType/Type/Font>> >> >>
Indirect Object Reference
Indirect objects are referenced and placed somewhere else inside the document. This requires PDF viewers to look the actual object up.
Indirect objects are defined in the PDF starting with their unique ID, an incrementing positive number, followed by a generative number, which is usually 0, along with the obj and endobj keywords.
This snippet shows how to define and use a font as an indirect object:
3 0 obj <</Name/Font1/BaseFont/Helvetica/Subtype/TrueType/Type/Font>> endobj 4 0 obj << /ProcSet[ /PDF /Text ] /Font <</Font1 3 0 R >> >> endobj
Cross Reference
Now the question arises: How does a PDF viewer look up where an indirect object is referenced? This is done via the cross reference table.
You might have noticed that at the bottom of the PDF is the startxref keyword. Since PDFs are read backward, from the bottom to the top, this keyword is defined at the bottom of the PDF rather than the top. The number after startxref states at which byte the cross reference (xref) table starts:
startxref 382
The actual cross reference table defines the location for every object in the PDF:
xref 0 6 0000000000 65535 f 0000000009 00000 n 0000000062 00000 n 0000000125 00000 n 0000000239 00000 n 0000000343 00000 n
The first line shows that the table contains the declaration for six objects. In addition to the location of every object in the document, it’s necessary to have an empty 0 object at the top. Since our example PDF has five objects, the cross reference table lists the location of six objects (including the empty 0 section). This makes it easy for PDF viewers to directly jump to the defined object without having to parse the entire document.
Learn More
In this article, we outlined some of the basic principles of how a PDF is structured internally, along with discussing how content that is rendered on a document page is defined and specified. To learn more about rendering in PSPDFKit or PDFs in general, head over to our guide about document rendering.

Stefan began his journey into iOS development in 2013 and has been passionate about it ever since. In his free time, he enjoys playing board and video games, spending time with his cats, and gardening on his balcony.