Our Approach to Testing a Large-Scale C++ Codebase

Testing is a crucial part of the software engineering process. No matter the size of the project you are working on, testing is essential to guarantee a minimum level of quality and adherence to a specification, to avoid regressions, and even to guide the software design process. There’s certainly a lot of public information about software testing, but in our approach to testing our large C++ codebase, we decided to avoid cookie-cutter solutions and instead be guided by two main aspects: some general testing principles we believe in, and the specific characteristics of our PDF engine. This article will discuss what the testing principles we apply are and how we are applying them at PSPDFKit.
Our Guiding Testing Principles
We focus on two important aspects of our software tests: their scope, and some quality metrics. I’ll explain what these two things mean in the next section.
The Scope of Tests, Classified According to the “Test Pyramid”
If you have experience with software testing, you have probably heard about the “test pyramid.” This pyramid is a metaphor that divides tests into buckets according to their granularity and gives you an idea about the approximate number of tests you should put in each bucket: The largest bucket of tests, represented by the base of the pyramid, should contain unit tests. The bucket above that, containing a smaller number of tests, should contain integration tests. And finally, the upper bucket, with the smallest number of tests in an application, should contain end-to-end tests. Here’s a graphical representation of the test pyramid.

Our View of the “Test Pyramid”
At PSPDFKit, we follow the test pyramid principle, but we don’t use the proposed nomenclature of unit, integration, and end-to-end. Instead, we prefer to refer to our tests as fine-grained, coarse-grained, and very coarse-grained. The reason is that there is not clear consensus on what’s represented by a unit, for example. Is it a function? A class or structure? A translation unit? Regarding specific technologies and frameworks, we use Google Test as the main testing framework for fine-grained, coarse-grained, and very coarse-grained tests.
One thing you may notice as you go from writing fine-grained tests to writing coarse-grained tests is that it’s probable that the way you test should also change, depending on the software component you are testing. At PSPDFKit, one of our most crucial components is a very complex PDF renderer written in C++. For testing this crucial component and avoiding regressions, we follow two approaches:
-
Covering the individual rendering components with fine-grained tests to ensure they work correctly.
-
Covering the integration of those individual rendering components with coarse-grained tests that check they work well together.
The main difficulties, in our opinion, arise with the second point. Rendering is a process that basically causes side effects: You pass a PDF document and a memory buffer to the render engine, and it modifies the memory buffer with the pixels that will be painted on the screen to represent the PDF document visually. Testing this process is difficult, and so to help with the testing, we have added another kind of test to our set of tests: screenshot tests.
Screenshot Tests Help Us Detect Visual Regressions
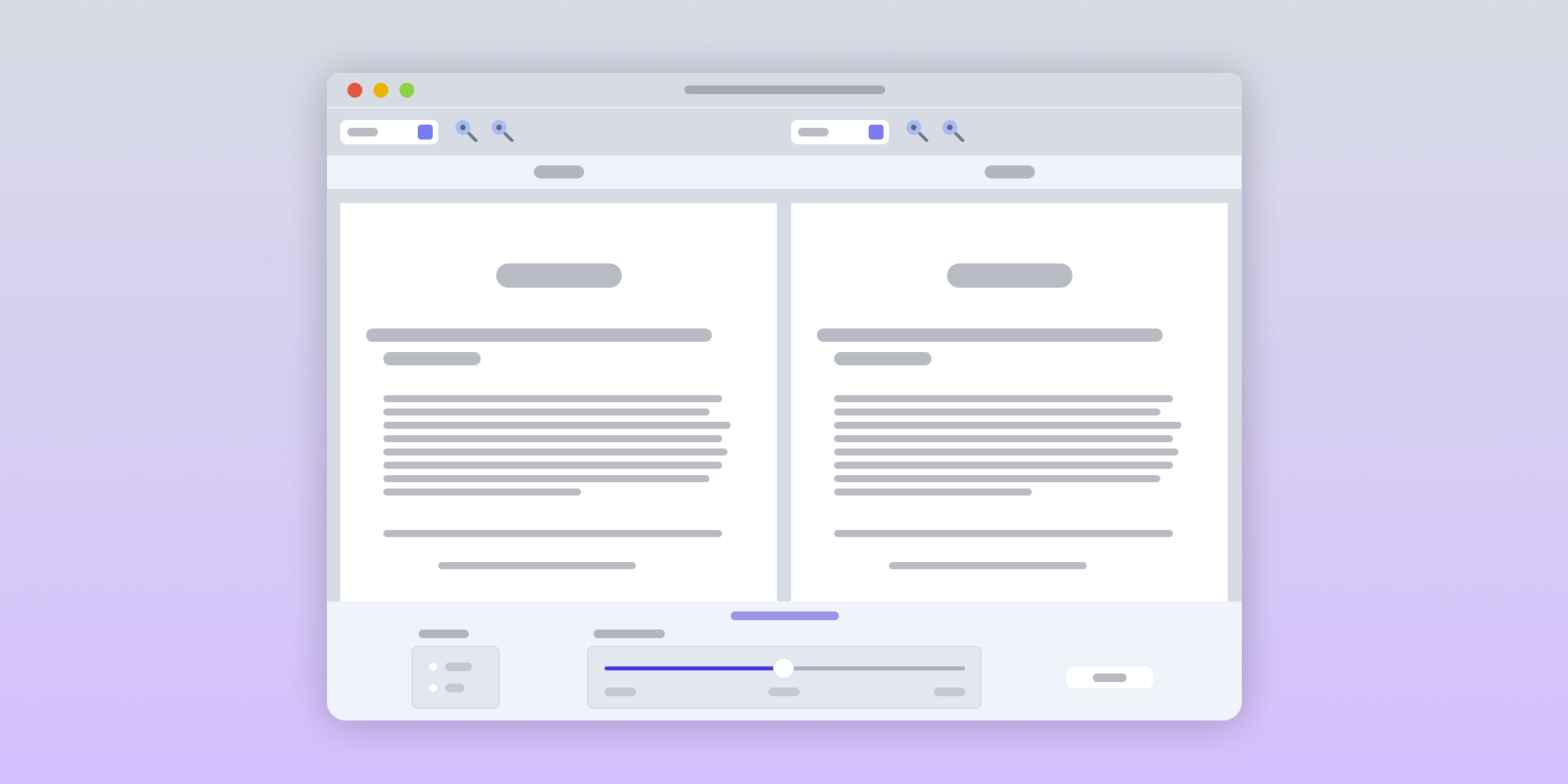
Screenshot tests are a special kind of test where images rendered by a program are compared against a reference image to detect visual regressions. We have developed an extension on top of Google Test that we use internally to support screenshot testing. This extension supports declaring the expected rendered images more easily (we can even specify images per platform), storing the failed ones in a specific folder, and introducing the concept of “pixel tolerance,” which is the maximum number of pixels in an image that may be different before we consider the rendered image incorrect.
💡 Tip: As different platforms have different fonts installed, using no text at all helps make the screenshot test more stable and require fewer changes to the reference images. Try to focus the screenshot on a small part of the user interface, with no text, if possible.
The decision on when to use a screenshot test or a regular coarse-grained test is sometimes difficult. The main question we ask ourselves is the following: “Am I interested in what the user sees on the screen or in whether the render engine produces some specific render instructions and not others?” With PDFs, different render instructions can produce the same visual aspect, so testing for some specific render instructions may not be the best way to test in all cases. Because of this, whenever we are more interested in testing that what the user sees on the screen is correct, we use a screenshot test.
Another typical question that we ask ourselves is: “If I add a screenshot test for this behavior, how often will the test break because of unrelated changes in other parts of the PDF engine?” One way to answer this question is to create screenshot test scenarios where the PDF file is the simplest one that reproduces a bug or showcases a feature. This is because using existing, usually complex, PDFs in screenshot tests, while quick, may introduce a screenshot test that would need to be updated a lot as the code in our application evolves.
Yet another important point to test is how your application handles input. When you are writing fine-grained tests, you are typically exercising pure functions or functions with very few side effects. That is, you pass some input to a component, the component returns a value, and the test asserts on that value. In many cases, the input for those functions comes from a PDF file, so we don’t have total control over the functions. This means that it’s very difficult to cover every possible input to our tests. It also means that we won’t be sure that some of these inputs are not actually malicious and causing our software to crash. To mitigate this uncertainty with unrestricted input, there’s a specific testing technique you can apply called “fuzzy testing.”
Fuzzy testing, or simply fuzzing, is a testing technique that provides a program with invalid input to check how it handles it. Specially crafted invalid input has been exploited for a long time by the software security research community to discover security vulnerabilities in C++ software. Fuzzy testing uses a genetic algorithm to create inputs and report the crashes it finds. The LLVM project provides its own implementation of fuzzy testing, libFuzzer. This library is included by default in recent versions of the Clang compiler.
Maintaining a High Test Quality Has a Compounding Effect in a Large-Scale Codebase
We think that keeping the quality of our tests high has a compounding effect in a codebase, especially if the codebase is big: People are more motivated to keep the quality of our tests high, workflows are more efficient, and regressions are identified promptly and resolved quickly. This is important when dozens of changes enter the codebase on a single day. But what do we mean by test quality?
Regarding the quality of our tests, we want them to be as fast as possible, as stable as possible, and as easy to write as possible. Let me explain these principles in more detail.
Tests Should Be as Fast as Possible
Nobody wants to wait hours for tests to finish. Having fast tests mean that they will be executed regularly and that we don’t have to wait long until a specific build of our software is considered “good.”
At PSPDFKit, we track the execution time of our tests and mark those that are “slow” (for example, a fine-grained test may be slow if it takes more than 1 second to execute). We regularly make detailed efforts to refactor the slow tests and make them faster. It’s usually the case that a slow test is also unstable, which is the topic of the next section.
Tests Should Be as Stable as Possible
Nobody wants tests that sometimes pass and sometimes do not pass, because they may hide real software regressions. But, no matter how hard you try, flaky tests will be written from time to time and introduced in your codebase. So, it’s important to have an approach in place to deal with them.
Fine-grained tests are typically more stable than coarse-grained tests, because the amount of code they test is lower. However, fine-grained tests may be unstable too, depending on how they are implemented. At PSPDFKit, we follow two approaches to avoid unstable tests. We:
-
Randomize the test execution order. This helps uncover and fix unwanted dependencies between tests. If you use Google Test, you can randomize the test execution order by passing the
--gtest_shuffleflag. -
Use test doubles for those parts of the code that we can’t reliably control from a unit test — for example, code that accesses the internet, or code that accesses a database. Test doubles are used in software testing to replace components in a production application with alternatives that behave specially in tests (for example, by accessing information locally instead of accessing information on the internet). We use the FakeIt library when we need to create C++ mocks.
What do we do when a flaky test is introduced in our C++ codebase? First of all, our continuous integration system is smart enough about certain kinds of errors that may be assumed to be caused by system instability and automatically retries them a few times. If the test continues to fail and we determine that the reason for the failure is not a software defect, we automatically consider the test to be “flaky,” disable it in the test suite, and create a bug report to fix it. We fix valid test failures or regressions not covered by one of our existing tests by performing git bisect to identify the commit that caused the regression. Then we revert it. We like to always keep the main development branch in a good state, and the corrected patch can be merged again later.
Tests Should Be as Easy to Write as Possible
Tests that are easy to write will be written more often. We try to identify parts of our tests where we write repetitive, verbose code, and we work to improve upon that by adding test helpers, test abstractions, etc. Investing time in this helps the next person who needs to write a test on that part of the codebase write it more efficiently.
Conclusion
PSPDFKit is a framework used by a lot of companies around the world, so we continually revisit our approach to testing to ensure the quality always remains high. What we’ve learned so far is that there’s no silver bullet in software testing. We recommend that you learn the testing principles, identify what’s most important in your application and dedicate enough testing resources to it, and create your own, pragmatic approach to testing that helps your company succeed.

Daniel is part of the Core Team at PSPDFKit and has worked on multiple topics, ranging from cryptography and text systems, to file format support and JavaScript engines. Outside of work, he likes spending time with his family, football, reading books, and watching films.