Testing Subjective Office Conversion Results
Ask any software developer, and they’ll tell you testing is a difficult subject. There are a lot of questions involved:
-
At what level do you test?
-
What percentage of coverage should you aim for?
-
Should you cover third-party software too?
-
Can the testing be automated?
-
At what stage of the process should tests be run?
The list goes on.
In this blog post, I’ll talk about a tricky testing situation where often, the test result isn’t a simple pass or fail. And the result can change depending on who, or what, is analyzing the test case.
A test case that never passes and never fails?! OK, so we have to add some tolerance — higher and lower guidelines — to define acceptable results? Well, that only solves half the equation; we still haven’t solved the subjective parameters of what constitutes a pass or fail.
To better understand this and explain the situation, let’s define the scope.
Converting between Digital Formats
At PSPDFKit, we offer conversion options for many formats: PDF to image, HTML to PDF, and — the topic of this blog post — Office to PDF, where Office refers to Word documents, Excel documents, and PowerPoint documents.
If you provide a Word document to convert to PDF, what result do you expect to get back? A PDF with the same contents, logically? Sadly, it’s not always that simple. That’s because features between the two digital formats don’t typically map in one-to-one relationships.
One example is that concepts like tables aren’t part of the PDF specification, whereas they are in Office. So to convert a table from a Word document to PDF, we have to use paths to draw the table with the correct representation and then place text in the exact location on the page that sits within the paths!
The issues don’t stop with mapping between the two formats — even interpreting the original Word document can present issues. The Word specification, OOXML, isn’t a format that instructs where to draw something. Instead it gives information to be interpreted by a parser, and it decides where an item should be drawn. That’s why you can open a document in Microsoft Office, and it’ll display differently than it does in other Office editors such as LibreOffice and Google Docs.
So when converting to a different format, how do you know if the result — which can be subjective — is correct? The simple answer is, you don’t. Instead, the answer is whether the user thinks it’s correct, or “good enough.” For some, that means they expect the exact representation that Microsoft Office displays, but for others, that means all data must be present in the result, but the fidelity of the result isn’t imperative.
This all goes to say: The result is subjective. And because it’s subjective, traditional pass/fail software testing doesn’t fit the bill.
How to Solve a Subjective Test Case
Now that we’ve determined there’s no right and wrong, and instead, we’re working in a gray area, we need a way of determining if the results produced are of an acceptable standard.
That’s where humans come in.
We know the subjective opinion of what’s right or wrong will come down to a human, i.e. the user, so what better way of determining the result than using said human?!
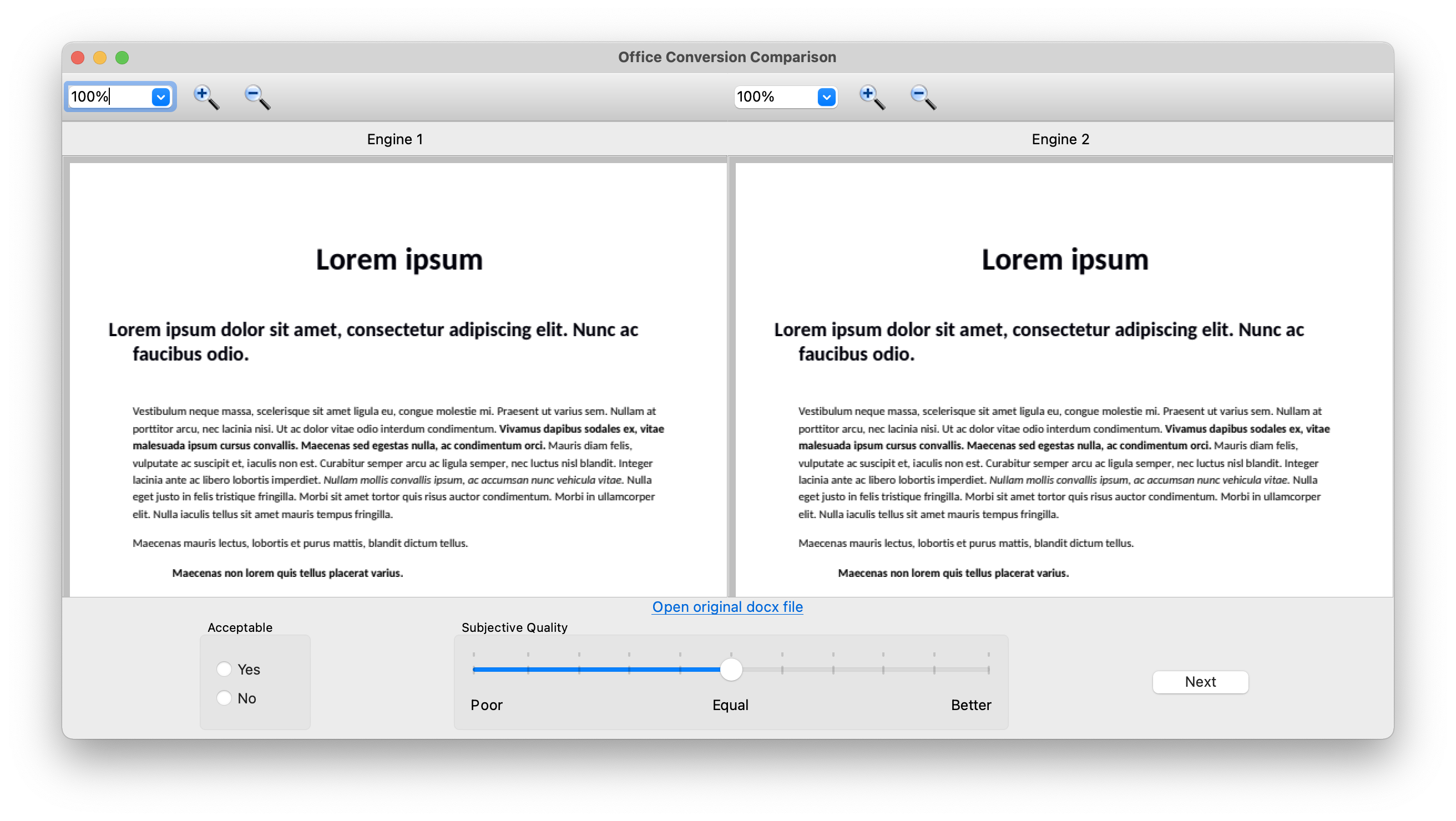
To do so, we at PSPDFKit had to create an internal tool to display the conversion result and ask the reviewer (in this case, yours truly) whether the result is what they expected. Then, the reviewer gave their subjective opinion on the fidelity of the result.
That’s not the whole story though; without any result to compare against, the human has no way of expressing if the test case is subjectively better or not. Therefore, we use different conversion engines for comparison.
The tool shows results from two conversion engines and asks the human to rate if one is better than the other, and if so, how much better is it. The given feedback equates to -100 to 100, where -100 is a hard fail for conversion engine 1, and 100 is a hard fail for conversion engine 2. If a result of 0 is given, then the conversions are deemed equal. We chose a -/+100 range to allow for better or worse representation that can easily convert to a percentage.
By analyzing multiple document conversions, we can then say that engine X is, on average, Y percent better than engine Z.
Tracking Fidelity Over Time
Comparing the output of two engines is a great option for creating a snapshot of fidelity at a given point, but it doesn’t give you a great indication of whether a single product has improved or regressed over time.
If fidelity over time is the metric of interest, then the testing method can be tweaked, and we can produce results from the same engine that are compiled from different points in time. We then compare the differences between the two results automatically, and we only perform human subjective tests on documents that have differences in results.
If the result stays the same, then you know the fidelity hasn’t changed either. In that case, you could say that the test passes.
When something changes, you can then perform the same subjective comparison method between the two results and determine whether the fidelity has improved or regressed.
Only assessing the differences between results speeds up the process dramatically, allowing us to implement an automated system to flag when differences are found. If no differences are found, we can immediately determine that the fidelity is the same and not waste any human time with subjective comparisons.
The tricky point is how to automatically compare the two results. Because the conversion engine is compiled from the same source, we can assume the results produced should be identical (not true for different conversion engines), thus we can use pixel comparison to find differences. Pixel comparison works OK, but in our tests, we go one step further and perform a glyph comparison to test whether the font metrics are the same (size, style, font name), and if the glyph positioning is identical. This form of testing works well, because it gives an indication of what textual information has changed, giving the human tester a hint of what differences to look for.
Conclusion
I hope that this post helped you question what results are testable. Even if you find yourself in a situation where results can be subjective, when you provide boundaries — or guidelines such as outputs — to compare against, it’s possible to produce numbers and outcomes that are actionable. And hopefully you can now see how software and automation don’t always have to be the answer. If a human can do a better or more deterministic job, allow them to!

When Nick started tinkering with guitar effects pedals, he didn’t realize it’d take him all the way to a career in software. He has worked on products that communicate with space, blast Metallica to packed stadiums, and enable millions to use documents through PSPDFKit, but in his personal life, he enjoys the simplicity of running in the mountains.