What’s Hiding in Your PDF?

PDF files hold lots of information. Most of the information contained in a PDF file is used to render a document in a reproducible way across many different platforms, be it a PDF of a contract, an instruction manual, or your favorite cat meme.
But did you know there’s also an abundance of metadata in a PDF with information about dates and times of creation and editing, what application was used, the subject of the document, the title and author, and more? These are examples of the standard set of metadata properties, but there are also ways to insert custom metadata into a PDF and insert hidden comments in the middle of the format. This post will introduce some different forms of metadata and show where to look for them.
Information Metadata
Since PDF 1.0, there has been a standardized set of values that can optionally be added to a document — file management systems use these values to provide a rich search experience. They include the following:
-
Author
-
CreationDate
-
Creator
-
Producer
In PDF 1.1, this set of values was further extended to include more pieces of data, which help enhance the discoverability of a document. They are:
-
Title
-
Subject
-
Keywords
-
ModDate
Strictly speaking, this information isn’t really hidden, as many applications allow you to view it. But to the general public, it’s not something that is immediately obvious. Either way, if security is a concern for you, caution should be taken when relying on this information, as it is also possible to edit at a later date. Because the metadata can be updated separate from the rendered content of the document, it means that your file management system and the document metadata may show a change, but the content may still be exactly the same.
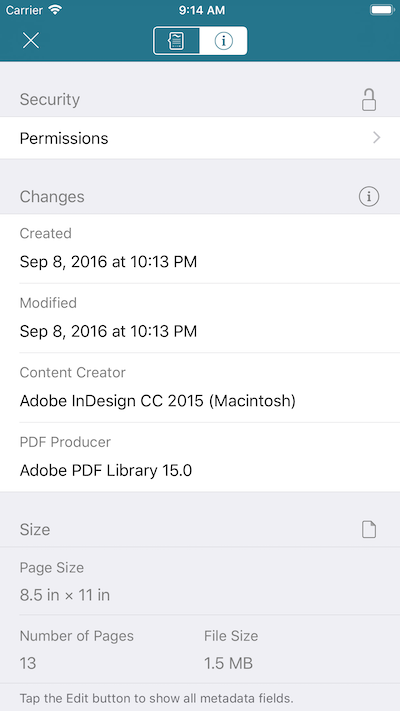
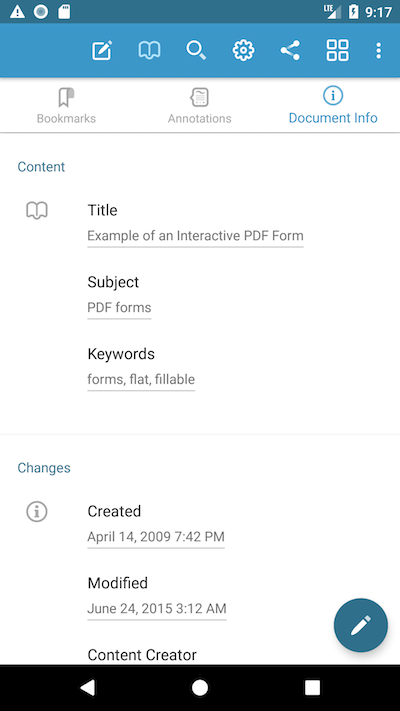
Extended Information Metadata
The PDF standard now supports more than just the above. Rather than the small set of dictionary defaults, it’s possible to hold a stream of information in the XMP format. As a result, any data type can be represented in metadata. Again, this metadata will not be rendered, but it may be parsed by file management systems.
The XMP stream may be encoded, so it’s not always readable by humans, though many applications can read and edit this information. Here is an example of what the XMP might look like in a format that’s readable by humans:
<xmp:CreateDate>1851-08-18</xmp:CreateDate>
<xmp:CreatorTool>Ink and Paper</xmp:CreatorTool>
<dc:creator>
<rdf:Seq>
<rdf:li>Nick Winder</rdf:li>
</rdf:Seq>
</dc:creator>
<dc:title>
<rdf:Alt>
<rdf:li xml:lang="x-default">My Amazing PDF</rdf:li>
</rdf:Alt>
</dc:title>As you can imagine, this information could be invaluable when trying to determine the document’s history or trying to embed some custom information that the document can be filed under. PSPDFKit for iOS and Android both support the reading and editing of metadata.
Metadata of Objects
Metadata streams are not only limited to documents; metadata can also be assigned to any object in a document. For example, the stream holding an embedded image can have related metadata. To complicate things more, auxiliary metadata can also be held in an image stream. To go even further, we can embed a PDF in image stream metadata, thereby achieving infinite recursion! So next time you’re checking that metadata for information, remember you may have to go multiple levels deep to find the information you really want.
Incremental Save/Update
The PDF standard has a concept of incremental saving, which many applications — including PSPDFKit — implement to speed up saving. In short, this method of saving will append extra information onto the end of a document, and the old objects that are no longer referenced will be left hanging. This is great when you are changing elements of a document on the fly and do not want to wait for a lengthy save process, or, for example, in our automatic saving feature where the process is run on a background thread and we want to use minimal resources.
As you can imagine, this could open up a whole can of worms when looking back at the history of a document to see if there is any sensitive or erroneous information that has been visually removed but is still left in the document. In these situations, it’s advisable to do a full save of the document. This will purge the old objects or even flatten the document so that Forms cannot be edited in the future.
PDF Comments
Just as many programming languages have comments to ensure the compiler or interpreter ignores a line, PDF also has a commenting option. The % symbol is used in various ways in the format, but it can also be used as a way to comment in a file. So if a user opens a document in a text editor, they may see some secret messages your PDF processor inserted. PDF renderers will ignore these commented lines so the file will still look correct and will not show any signs of commented text in the rendered image.
One Big Dictionary!
The last thing to note is that the PDF format is actually one big dictionary! So technically, anyone/anything can go into the document and change something behind the scenes. Not every change is as easy as a line change, but it can be done. For this reason, you should always be sensitive about what information could be lurking in the PDF you are looking at. Additionally, if you are handling confidential information, you should use Digital Signatures to ensure that the document has not been modified by someone other than its author, and to verify that the author is who you expect and not somebody else.
Conclusion
This blog post shows some ways metadata can sneak into your document without you knowing. There are also other factors to take into account, such as JavaScript support within PDF. With JavaScript, the options are endless. Hidden objects can also be held by documents, which are usually parsed but not rendered. This can be a good way of injecting some type of information into the PDF parser. PDF is such an extensive standard, so it always pays to know and trust your PDF software.

When Nick started tinkering with guitar effects pedals, he didn’t realize it’d take him all the way to a career in software. He has worked on products that communicate with space, blast Metallica to packed stadiums, and enable millions to use documents through PSPDFKit, but in his personal life, he enjoys the simplicity of running in the mountains.