Rendering PDF Files in the Browser with PDF.js

PDF files are commonly used in many businesses today — whether you want to generate sales reports, deliver contracts, or send invoices, PDF is the file type of choice. In an earlier post, we looked at a native solution that works on many browsers without the use of JavaScript or any third-party browser plugins.
In this tutorial, we’ll go a bit deeper and examine one of the most popular open source libraries for rendering PDF files in the browser: PDF.js. We’ll walk you through how to render a PDF and how to embed a PDF viewer in the browser, and at the end, we’ll discuss cases in which you should opt for a commercial Javascript PDF Viewer.
Displaying a PDF in the Browser with PDF.js
PDF.js is a JavaScript library written by Mozilla. Since it implements PDF rendering in vanilla JavaScript, it has cross-browser compatibility and doesn’t require additional plugins to be installed. We suggest carefully testing correctness, as there are many known problems with the render fidelity of PDF.js.
How Does PDF.js Handle PDFs?
With PDF.js, PDFs are downloaded via AJAX and rendered in a <canvas> element using native drawing commands. To improve performance, a lot of the processing work happens in a web worker, where the work of the core layer usually takes place.
PDF.js consists of three different layers:
-
Core — The binary format of a PDF is interpreted in this layer. Using the layer directly is considered advanced usage.
-
Display — This layer builds upon the core layer and exposes an easy-to-use interface for most day-to-day work.
-
Viewer — In addition to providing a programmatic API, PDF.js also comes with a ready-to-use user interface that includes support for search, rotation, a thumbnail sidebar, and many other things.
To get started, all you need to do is to download a recent copy of PDF.js and you’re good to go!
![]()
Rendering a PDF
To render a specific page of a PDF into a <canvas> element, we can use the display layer. We first extract all the files in the downloaded copy of PDF.js, but we currently only need the files pdf.js and pdf.worker.js from the build/ folder of the download. We move these files into a new empty directory, which allows us to create a simple.js and a simple.html file.
The HTML file needs to point to the pdf.js source code and to our custom application code (simple.js). We also create a <canvas> element, which we want the first page of the PDF to be rendered into:
<!-- simple.html --> <!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>PDF.js Example</title> <script src="/pdf.js"></script> <script src="/simple.js"></script> </head> <body> <canvas id="pdf"></canvas> </body> </html>
Now all that’s missing is our simple.js code that leverages the PDF.js API to render the first page. This API makes heavy use of Promise, a JavaScript feature for handling future values. If you’re not familiar with this pattern, you should check out the MDN web docs.
The getDocument(url) method can be used to initialize a PDF document from a URL. From there, we can access a single page via the page(pageNumber) method (pageNumber starts at 1 for the first page, etc.). The getViewport(scale) method can be used to get the dimensions of a PDF that are multiplied by the scale factor. We use the viewport information to set the dimensions of the <canvas> element and can then start the page renderer with the render(options) API:
// simple.js (async () => { const loadingTask = PDFJS.getDocument('/test.pdf'); const pdf = await loadingTask.promise; // Load information from the first page. const page = await pdf.getPage(1); const scale = 1; const viewport = page.getViewport(scale); // Apply page dimensions to the `<canvas>` element. const canvas = document.getElementById('pdf'); const context = canvas.getContext('2d'); canvas.height = viewport.height; canvas.width = viewport.width; // Render the page into the `<canvas>` element. const renderContext = { canvasContext: context, viewport: viewport, }; await page.render(renderContext); console.log('Page rendered!'); })();
// simple.js var loadingTask = PDFJS.getDocument('/test.pdf'); loadingTask.promise.then( function (pdf) { // Load information from the first page. pdf.getPage(1).then(function (page) { var scale = 1; var viewport = page.getViewport(scale); // Apply page dimensions to the `<canvas>` element. var canvas = document.getElementById('pdf'); var context = canvas.getContext('2d'); canvas.height = viewport.height; canvas.width = viewport.width; // Render the page into the `<canvas>` element. var renderContext = { canvasContext: context, viewport: viewport, }; page.render(renderContext).then(function () { console.log('Page rendered!'); }); }); }, function (reason) { console.error(reason); }, );
Before you run this code, make sure to copy a PDF file into the folder and rename it to test.pdf.
Then, to run this code, start a web server in your test directory. If you’re on a system that has a recent version of Python preinstalled (like macOS), you can use python -m SimpleHTTPServer 8000. Next, open the example at localhost:8000/simple.html.
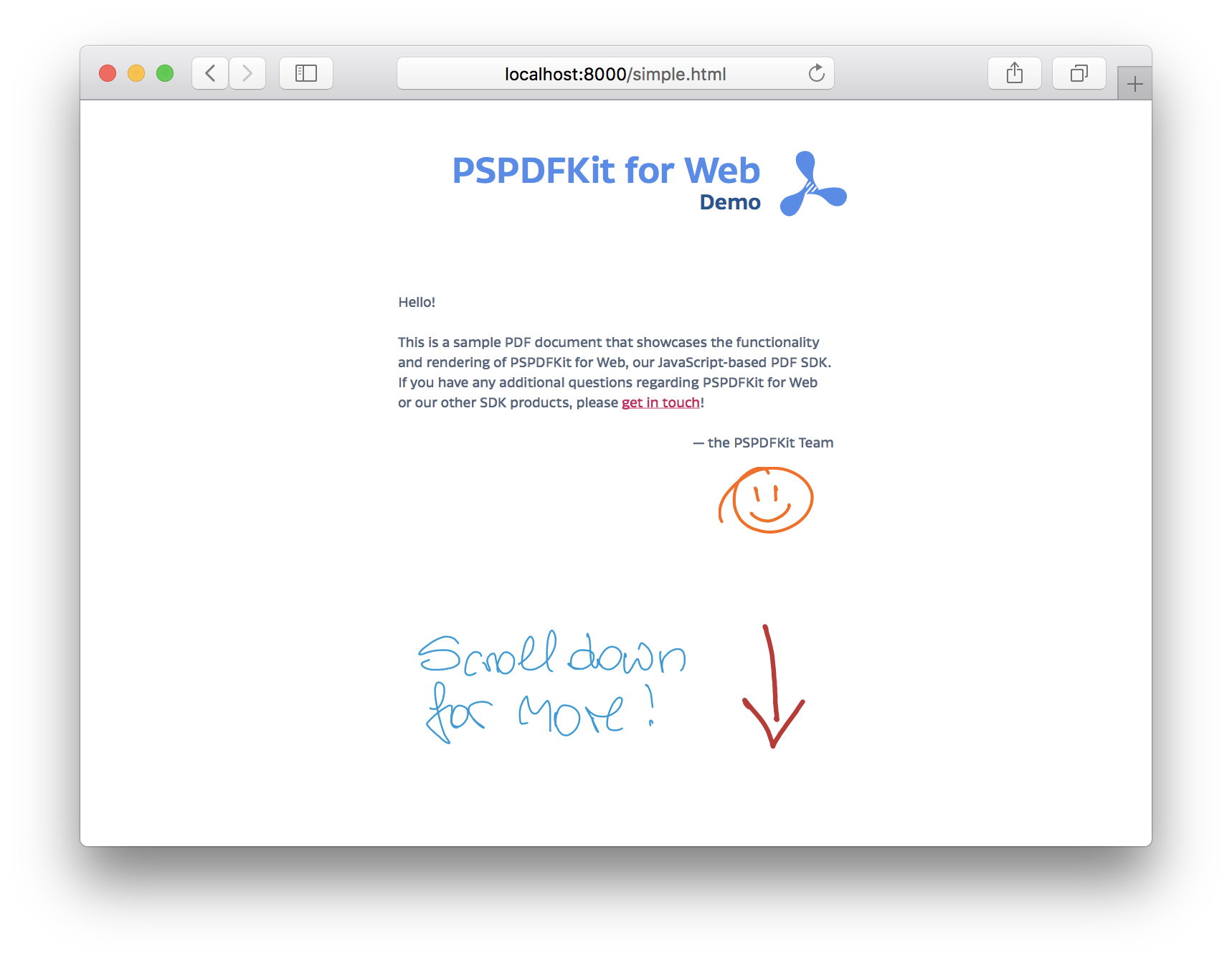
Embedding the PDF Viewer in an HTML Window
While the display layer provides fine-grained control over which parts of a PDF document are rendered, there are times when we prefer a ready-to-use viewer. Luckily, PDF.js has us covered. In this part, we’ll integrate the PDF.js default viewer into our website.
Looking at the downloaded files, we see another directory, web/. In this directory, we can find all necessary files for the viewer. We copy the entire folder into a new directory called viewer/ (which results in files like viewer/web/viewer.js).
Just like in the previous example, we need the JavaScript files of PDF.js. To set this up correctly, we create the build/ folder inside viewer/ and copy the files there, which results in viewer/build/pdf.js and viewer/build/pdf.worker.js.
We can now work on the integration. To do this, we create a simple HTML file that will include the viewer via an <iframe>. This allows us to embed the viewer into an existing webpage very easily. The viewer is configured via URL parameters, a list of which can be found here. For our example, we’ll only configure the source PDF file. For more advanced features (like saving the PDF document to your web server again), you can start modifying the viewer.html file provided by PDF.js:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title>PDF.js Example</title> </head> <body> <iframe src="/web/viewer.html?file=/test.pdf" width="800px" height="600px" style="border: none;" /> </body> </html>
This tiny block of HTML is indeed all that’s needed to start working, and all of the PDF.js code is handled conveniently via the viewer.html file delivered by PDF.js. Now copy a PDF file to viewer/test.pdf and start a simple HTTP server inside the viewer/ directory again.

Conclusion
The three layers of PDF.js are nicely separated, allowing you to focus on the parts you really need. The core layer handles the heavy PDF.js parsing — an operation which usually takes place in a web worker. This helps keep the main thread responsive at all times. The display layer exposes an interface to easily render a PDF, and you can use this API to render a page into a <canvas> element with only a couple of lines of JavaScript. The third layer, viewer, builds upon the other layers and provides a simple but effective user interface for showing PDF documents in a web browser.
All in all, PDF.js is a great solution for many use cases. However, sometimes your business requires more complex features, such as the following, for handling PDFs in the browser:
-
PDF annotation support — PDF.js will only render annotations that were already in the source file, and you can use the core API to access raw annotation data. It doesn’t have annotation editing support, so your users won’t be able to create, update, or delete annotations to review a PDF document.
-
PDF form filling — While PDF.js has started working with interactive forms, our testing found that there are still a lot of issues left open. For example, form buttons and actions aren’t supported, making it impossible to submit forms to your web service.
-
Mobile support — PDF.js comes with a clean mobile interface, but it misses features that provide a great user experience and are expected nowadays, like pinch-to-zoom. Additionally, downloading an entire PDF document for mobile devices might result in a big performance penalty.
-
Persistent management — With PDF.js, there’s no option to easily share, edit, and annotate PDF documents across a broad variety of devices (whether it be other web browsers, native apps, or more). If your business relies on this service, consider looking into a dedicated annotation syncing framework like PSPDFKit Instant.
-
Digital signatures — PDF.js currently has no support for digital signatures, which are used to verify the authenticity of a filled-out PDF.
-
Advanced view options — The PDF.js viewer only supports a continuous page view mode, wherein all pages are laid out in a list and the user can scroll through them vertically. Single- or double-page modes — where only one (or two) pages are shown at once (a common option to make it easier to read books or magazines) — aren’t possible.
-
Render fidelity - There are many known problems with the render fidelity of PDF.js, where PDFs look different, have different colors or shapes, or even miss parts of the document altogether.
If your business relies on any of the above features, consider looking into alternatives. We at PSPDFKit work on the next generation of PDF viewers for the web. Together with PSPDFKit Instant, we offer an enterprise-ready PDF solution for web browsers and other platforms, along with industry-leading first-class support included with every plan. Launch our Web demo to see PSPDFKit for Web in action.