Parse PDF Content on iOS
Parsing text and other content from a PDF can be a complex task, so we offer several abstractions to make this simpler. In a PDF, the text usually consists of glyphs that are positioned at absolute coordinates without any relative association with neighboring glyphs. PSPDFKit heuristically splits these glyphs up into words and blocks of the text. Our user interface leverages this information to allow users to select and annotate text. You can read more about this in our Text Selection guide.
Text Parser
TextParser offers APIs to get the text, glyphs (Glyph), words (Word), textBlocks (TextBlock), and even images (ImageInfo) from a given PDF page. Every page of a PDF has a text parser that returns information about the text on a page:
let document: Document = ... let textParser = document.textParserForPage(at: 0)! let glyphs = textParser.glyphs
PSPDFDocument *document = ...;
PSPDFTextParser *textParser = [document textParserForPageAtIndex:0];
NSArray<PSPDFGlyph *> *glyphs = textParser.glyphs;TextParser also ensures that the text it extracts from a PDF follows any logical structure defined in the PDF (see section 14.7 of the PDF specification), thereby enabling support for correctly handling different text-writing directions.
Glyphs, Text Blocks, Words, and Images
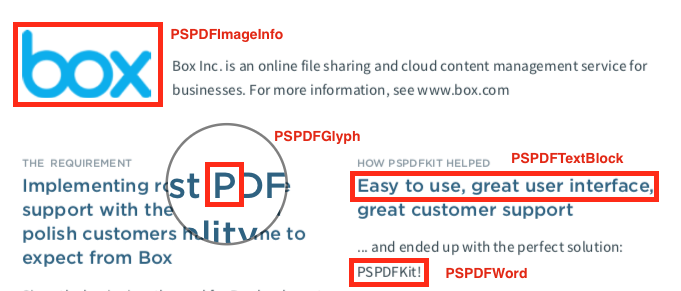
Glyphs
The Glyph object is the building block for all text extraction in PSPDFKit. It represents a single glyph on a PDF page. Its frame property specifies, in PDF coordinates, where it’s located on the page, and its content property returns the text it contains. The indexOnPage property specifies the index of the glyph on the page, in reading order. Consider a page with the following text:
The quick brown fox jumps over the lazy dog. --------------------------^
The Glyph that represents the o in over will have an indexOnPage of 26. This index is unique to this glyph, and it can be used to directly access it from the glyphs array of a TextParser:
let document: Document = ... let textParser = document.textParserForPage(at: 0)! let glyphs = textParser.glyphs let glyph = glyphs[26] // Guaranteed to be `true`. let indexEqualTo26 = (glyph.indexOnPage == 26)
PSPDFDocument *document = ...; PSPDFTextParser *textParser = [document textParserForPageAtIndex:0]; NSArray<PSPDFGlyph *> *glyphs = textParser.glyphs; PSPDFGlyph *glyph = glyphs[26]; // Guaranteed to be `YES`. BOOL indexEqualTo26 = (glyph.indexOnPage == 26);
This makes getting a particular glyph (and glyphs near it) much faster, as you already know the index. Ordering glyphs correctly is important if, for example, you wish to combine multiple glyphs and display something to the user.
Text Blocks
A TextBlock returned from the TextParser represents a contiguous group of glyphs, usually in a single line. For PDFs with multiple columns of text, a text block is a single line in a given column. TextBlock is backed by an NSRange (TextBlock.range) that describes the range of glyphs in TextParser.glyphs that the block represents. The same information is available for a Word via Word.range.
To fetch the glyphs associated with a given text block, retrieve them from TextParser.glyphs:
let block: TextBlock? = ... let parser: TextParser = ... let glyphs: [Glyph] = parser.glyphs(in: block.range)
PSPDFTextBlock *block = ...; PSPDFTextParser *parser = ...; NSArray<PSPDFGlyph *> *glyphsInBlock = [parser glyphsInRange:block.range];
Words
A Word, as the name suggests, represents a single word in a PDF. TextParser automatically generates these words when parsing the text blocks, and they can be retrieved via the words property. You can also access the words in a particular text block via the TextBlock.words property.
Images
The TextParser API also supports extracting images from PDF pages. To learn more about how to do that, please refer to the Image Extraction guide.