OMR in C#
Optical mark recognition (also called optical mark reading or OMR) is the process of using hardware, software, or both to capture fields — for example, marks on documents such as multiple choice questions, questionnaires with true or false fields, and other document forms.
GdPicture.NET Library enables you to scan these kinds of documents and determine if fields are filled in or not.
Components of a Software OMR System
Each OMR system has two main components.
Template
This usually is a non-filled document where you specify the location of the data you want to extract. This data is split into two parts:
-
Anchor — A logo, black rectangle, or solid object at the edge of the document that repeats on every filled form.
-
OMR Fields — The locations of the fields that need to be filled in. GdPicture.NET uses rectangles surrounding the fields to specify their location for the recognition algorithm.
Scanned Forms
These are the same forms as the template, but with the human-marked data on them. In other words, they’re the documents we want to extract information from.
Types of OMR Fields
There are numerous types of OMR fields, but this section will give an overview of some of the most common ones.
There can be shapes, like squares, circles, and ovals.
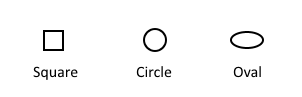
On multiple choice exams, these shapes often have characters — such as numbers or letters — inside of them.
![]()
Regardless of the shape, OMR can recognize them as long as you specify the shape and whether or not it contains a character.
Problems Causing Bad OMR
There are three known issues that can affect the quality of OMR:
-
Low DPI Images — These are images with 150 dots per pixel or less. They affect the quality of images and, in turn, the quality of the OMR fields and the content inside them.
-
Small Fields — If the OMR fields are too small, in many cases, the decision process will depend on just a few pixels. This means the data available to the recognition algorithm will be too small to make an accurate decision, resulting in a larger margin of error.
-
Translation Due to Scanning — The locations of the OMR fields in a scanned filled document will never be the same as the locations specified in the template document:
-
The location of a document in the scanner will never be exactly the same as the location of the template document in the scanner.
-
Stretching along both axes due to the feeding mechanism in the automatic document feeder of the scanner, if it’s used.
-
The first two problems can easily be remedied when designing a form by scanning at 200–300 DPI and making the OMR fields large enough to contain more than a few pixels. For the third problem, GdPicture.NET Library has an anchoring engine that helps measure this translation and amend your data locations.
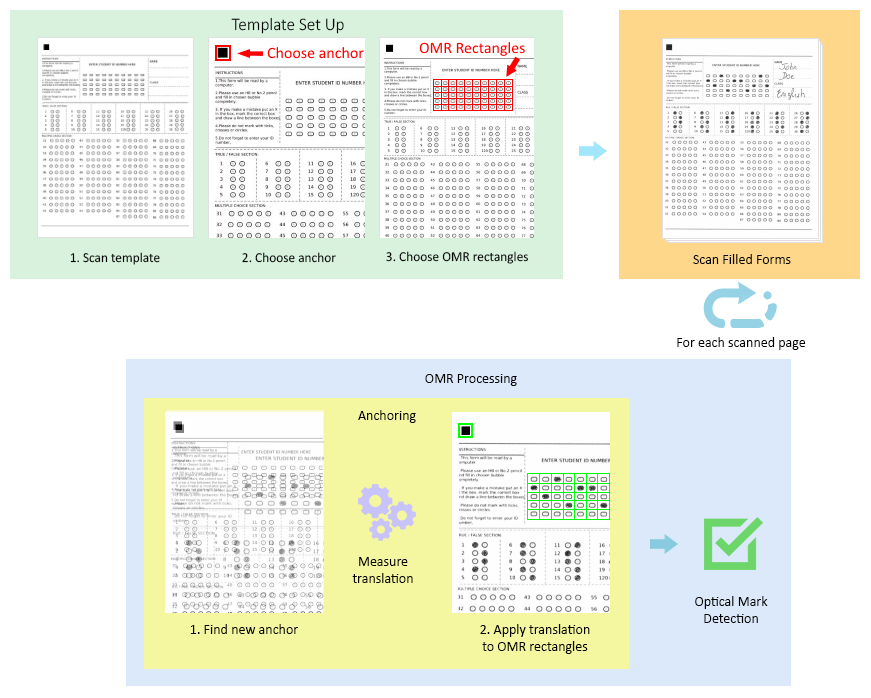
Anchoring: Overcoming the Translation Problem
One part of the template form is the anchor, which is a logo, rectangle, or solid object, and it’s used to measure translation between the template document and the scanned filled forms.
The idea behind choosing this is that, regardless of the sampling used, it shows up on every document with enough data (black pixels) for it to be recognized.
By searching for, finding, and registering the location of this anchor, we can compare its new location to its location in the template document.
The difference between the two locations in the X and Y axes is the translation. This translation is the translation of the whole document.
Now, if this translation is applied to the OMR field rectangles specified in the template document, they’ll be at their correct location, and in turn, we’ll know the location of the OMR fields in the filled document.
The images below show this process, beginning with setting up the template, and ending with detecting optical marks.