Why PDF Uses Floats and Word Uses EMUs
 Markus Woschank
Markus Woschank
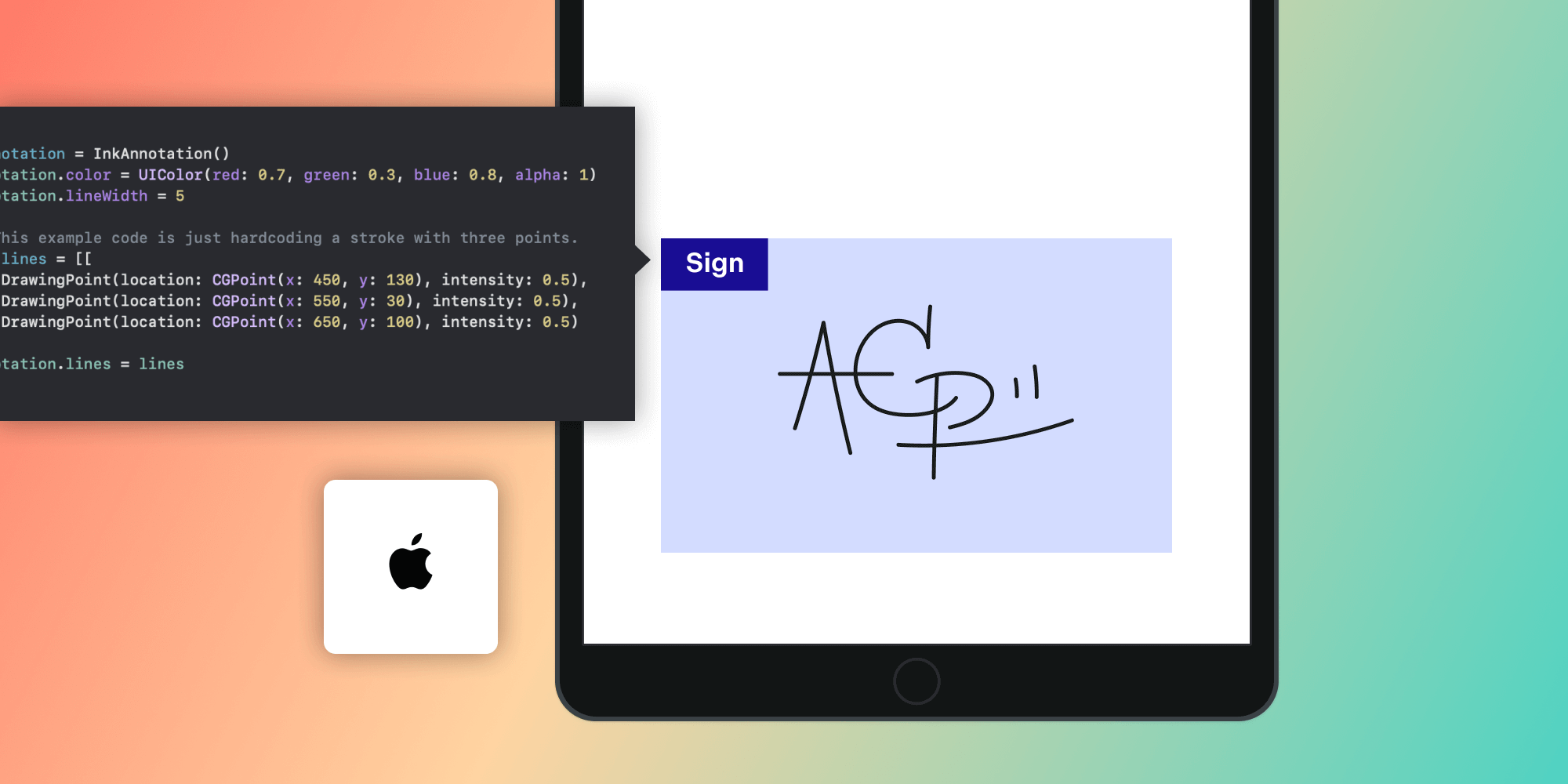
When dealing with Microsoft Office documents, it’s common to encounter many different units of length, most of which are constrained to integer values. In contrast, PDFs almost always specify real (as in a mathematical real number) values. Furthermore, in PDFs, there are only a few different contexts where the same number has a different meaning.
This post will give some examples of the units of length in Word documents and discuss why the choice of integers vs. real values might make sense for each domain.
Units of Length in a Word Document
This next section will cover units of length used in Office and Word documents.
Integer-Only by Default
By default, Word will store integer-only values for the following:
-
point
This is the smallest unit of measure from typography with a de facto standard size of 1/72 inch. The space between a table border and cell content is specified in points.
-
half point
This is, as the name says, half a point. Word uses it for the font size. Fun fact: Word will inform you that 11.6 is not a valid number when entered as a font point size, whereas 11.5 is fine and can be used.
-
eighth point
The Office Open XML (OOXML) standard loves to divide points down even further. You can specify the width of page borders in eighths of a point.
-
twip
Line heights get a little more precision than font sizes or page border widths. They can be specified in twentieths of a point.
-
pixel
You can even specify the dimensions of some elements on the page in pixels. Depending on the context, this can have a different meaning.
-
English Metric Unit (EMU)
This is the base unit for DrawingML, which deals with shapes and the positioning of graphical elements. It’s defined as 1 EMU = 1/914400 imperial inch = 1/360000 cm.
We’ll discuss EMUs in a moment.
Additional Units Not Used by Default
The OOXML standard permits specifying real values for some of the above units, and the following units can also be specified with real values, although Word will usually not generate documents containing them.
-
pica
Typographic unit of measure corresponding to approximately 1/6 of an inch. There are three different measures in use today (American, French, and PostScript). A pica is further divided into 12 points. Want to specify the height of a shape? Why not use picas?
-
inch
This is the imperial inch, which is based on the international yard, which in turn is defined based on the metric system and defined exactly as 1 inch = 25.4 mm.
-
cm
-
mm
These are boring measures based on the metric system. 1 cm = 10 mm.
-
em
-
ex
These are the same as in CSS: em refers to the height of the element’s font, and ex refers to the height of the letter x of the element’s font.
English Metric Unit
This is what it boils down to: one unit to rule them all (well, almost all).
Let’s just quote the standard here: “The EMU was created in order to be able to evenly divide in both English and Metric units, in order to avoid rounding errors during the calculation. The usage of EMUs also facilitates a more seamless system switch and interoperability between different locales utilizing different units of measurement. EMUs define an integer based, high precision coordinate system.”
Although it doesn’t work out for every unit, most integer input values can be converted into EMUs without rounding (and therefore without loss of information) using only integer-based data types:
| 1 | EMUs |
|---|---|
| inch | 914400 |
| pica | 152400 |
| point | 12700 |
| half point | 6350 |
| eighth point | 1587.5 |
| twip | 635 |
| cm | 360000 |
| mm | 36000 |
| pixel @96DPI | 9525 |
Integers Everywhere
The pattern of using integers and not real numbers to specify values continues for other measures too, for example:
-
thousands of an arcminute
Image rotations are specified in this unit.
-
thousands of a percent
If a percentage needs to be specified, just multiply it by 1,000 and forget the rest.
Integers vs. Reals
While Word and the whole Office suite prefer integer-only values, the PDF specification and documents almost always use real numbers to specify values for layout elements like font size, positioning, etc. Why is that? It comes down to decimal vs. binary and rounding.
Fractions and Numeral Systems
We humans are fond of and mostly use the decimal system, while computers mostly use the binary number system. This has some implications because different numeral systems can’t represent the same set of numbers using only a finite number of digits. For example, just as we can’t represent 1/3 in the decimal system using a finite number of digits, computers can’t represent 1/10 accurately using a finite number of bits.
This means if we would, for example, specify the line height of a paragraph as 0.1 points (because who needs the fine print, right?) and put 10 lines on the page, then Word will need to save this information in the document. File formats often use the decimal system for storing numbers, as does OOXML, even though computers don’t normally use this number system for calculations. So Word would store the line height as 0.1 in the decimal system in the document.
But if a word processor reads that back in, it has to convert this number into binary, which will involve some rounding, and it won’t be stored in memory as exactly 0.1, but as slightly more or less. This in turn means that the accumulated height of the 10 lines will be either slightly more or slightly less than 1. That’s a problem for Word documents, as there might only be space for, let’s say, exactly 1 (in whatever unit). And depending on the height of the 10 lines, the paragraph might need to break and continue on the next page — or not.
Rounding and Order of Operations
So we need to round numbers because of fractions, but it gets worse, as the order we’re executing operations in will also affect the outcome. For example, 2*(1/2) will equal 0, while (2*1)/2 will equal 1 on almost all computers using integers. For floating-point systems, this gets worse because even additions may need rounding: 1e30-(1e30+1e-30) will yield 0, while (1e30-1e30)+1e-30 will yield 1e-30 using floats on current hardware.
Parsing Reals Is Really Hard
With IEEE 754, almost all modern CPUs should give the same results when doing floating-point math. But there’s another issue: It turns out parsing reals to floating-point numbers is really hard. You want your reals parser to yield the exact same value on all platforms and CPU architectures given the same string. Amazingly, .NET Core struggled with this until at least .NET Core 3.0.
If we look at rendering floating-point numbers as strings, it’s surprising again how difficult this problem is. You can use an algorithm called Grisu3, which can quickly convert 99.5 percent of floating-point numbers to strings, but you have to revert to an older, slower algorithm called Dragon4 for the remaining tricky cases.
On top of that, the rendered string should yield the exact same number when it’s parsed again.
Reals for PDF
In contrast to Word documents, PDFs don’t need to lay out content. In general, there’s a clearly defined way of deriving each element’s position, and if the position or size of that element turns out slightly different on different platforms, it has no consequences on the rest of the document.
Conclusion
The zoo of different units of length in Word is probably there for historical reasons as, for example, just using EMUs everywhere would be sufficient. Floating-point numbers introduce a lot of pitfalls if reproducibility is required. Reproducibility is important for Word and Office documents, as minor differences in reconstructing the elements of a document can heavily influence the appearance of the rest of the document. As such, the preference of integer-only values makes sense in this domain. For PDFs, just using floating-point numbers is fine, and not having to deal with, for example, building transformation matrices from integers is much easier.
Markus loves to build things. He’s learned way too many things about document formats and text systems since he joined in 2019.