Extracting Key-Value Pairs Using GdPicture.NET SDK


This article will cover what key-value pairs (KVPs) are, how they’re used, and how GdPicture.NET’s KVP extraction engine extracts them from documents that contain unstructured data.
What Are Key-Value Pairs?
In the context of a document, key-value pairs are a way of organizing data or information. These pairs are made up of keys and values. Depending on the type of document, the key-value pairs can be different.
For example, key-value pairs on invoices can be the following:
| Key | Value |
|---|---|
| Invoice Number | No 00162 |
| Billing Date | 20/09/2022 |
| Total | 1,165.10€ |
Here’s an example of key-value pair fields on a government form:
| Key | Value |
|---|---|
| Company Name | PSPDFKit GmbH |
| Registration Number | FN 548939p |
| Date of Incorporation | 04/10/2013 |
Extracting Key-Value Pairs
It’s easy to get key-value pairs from structured documents like Excel files because the values are all named. However, a majority of documents have unstructured data. For these documents, a KVP extraction tool is required to retrieve the information. Intelligent document processing (IDP) extracts data from unstructured and semi-structured documents using optical character recognition (OCR) and artificial intelligence (AI) technologies.
In such cases, the extraction of key-value pairs involves two tasks:
-
Using OCR technology to recognize unstructured information and text in a document.
-
Using machine learning (ML) and deep learning (DL) to make sense of the unstructured information by composing links between different parts of the extracted text.
The next sections will talk about why these two approaches have limitations when used separately, as well as why they should be combined for the most reliable results.
The Disadvantages of Only Using Traditional OCR
Extracting data with the traditional OCR approach is based on heuristics. The most important limitation of the traditional OCR approach is that it needs to use a different template for each document type. This works well for simple documents with structured data. However, extracting data with the traditional OCR approach doesn’t perform well with unstructured or semi-structured documents.
Extracting data with this approach suffers from the same limitations as traditional OCR engines that have difficulties recognizing text in the following contexts:
-
Colored backgrounds
-
Glaring
-
Skew
-
Text in tables and graphics
-
Handwritten text
The Disadvantages of Only Using Machine Learning and Deep Learning
Data extraction solutions that leverage ML and deep learning use AI technologies to mitigate the traditional OCR limitations. These deep learning approaches are usually a combination of different techniques such as convolutional neural networks, long short-term memory layers, transformers, and graph neural networks.
However, this approach has a few drawbacks compared to traditional OCR:
-
Time — You’ll need to spend a lot of time teaching ML/DL how to perform under the specific parameters you need.
-
Fixing errors — In the same vein, it can be hard and take a long time to “unteach” incorrect results.
-
Speed and resource usage — Traditional OCR can work more quickly on smaller systems with fewer resources needed compared to ML/DL approaches.
Additionally, data extraction relying only on machine and deep learning often fails for documents with a lot of noise and dotted lines.
GdPicture.NET’s Key-Value Pair Extraction Engine
A combination of the approaches above is necessary to achieve the best results in data extraction. For this reason, PSPDFKit GdPicture.NET recognizes text and key-value pairs based on a hybrid approach of the following methods:
-
Heuristics
-
Mathematics
-
Machine learning
This approach produces superior results compared to traditional OCR and pure ML approaches.
GdPicture.NET’s key-value pair extraction engine enables you to recognize related data items — such as IBANs and addresses — in a document and export them to an external destination like a spreadsheet. GdPicture.NET automatically recognizes the document type, such as a bank statement, and adapts to the context and determines the extraction approach that makes the best use of available resources. It also recognizes the document type based on adaptive layout understanding and natural language processing (NLP) technologies.
GdPicture.NET Data Model
The GdPicture.NET data model enables you to extract data from documents with excellent results. GdPicture.NET’s hybrid approach performs better than traditional OCR and pure ML engines, especially for documents with the following features:
-
Noise
-
Dotted lines
-
Broken characters
-
Text on colored backgrounds
-
Underlined text
-
Skewed text
-
Text in graphics and tables
Confidence Score — How We Ensure Extraction Accuracy
PSPDFKit GdPicture.NET’s key-value pair extraction engine calculates a confidence score, which expresses how confident the engine is in the accuracy of the extracted data.
The confidence score is calculated by considering the following factors, among others:
-
The confidence in the OCR result at the character level. Some characters are more difficult to recognize than others.
-
The confidence in the OCR result at the word level. Some words are more difficult to recognize than others.
-
The data type of the key. Some data types are more difficult to recognize than others. For example, dates and IBANs are relatively easy to recognize, while phone numbers and addresses are generally more difficult.
The confidence score enables you to filter results based on their assumed accuracy. For example, you can disregard data extraction results with a low confidence score, or flag them as data items that require manual checks.
Data Types We Can Categorize
PSPDFKit GdPicture.NET’s KVP extraction engine automatically detects the data type of values. The following data types are supported:
-
Business Identifier Code (BIC)
-
Credit card number
-
Currency
-
Date and time
-
Email address
-
International Bank Account Number (IBAN)
-
Number
-
Percentage
-
Phone number
-
Postal address
-
Postal code
-
String
-
Symbol
-
Time period
-
Unique Identifier (UID)
-
URL
-
Vat ID
How to Extract Data from Invoices
To extract data items from an invoice, follow these steps:
-
Create a
GdPictureOCRobject and aGdPictureImagingobject. -
Select the invoice by passing its path to the
CreateGdPictureImageFromFilemethod of theGdPictureImagingobject. -
Configure the OCR process with the
GdPictureOCRobject in the following way:-
Set the invoice with the
SetImagemethod. -
Set the path to the OCR resource folder with the
ResourceFolderproperty. The default language resources are located inGdPicture.NET 14\Redist\OCR. For more information on adding language resources, see the language support guide. -
With the
AddLanguagemethod, add the language resources that GdPicture.NET uses to recognize text in the image. This method takes a member of theOCRLanguageenumeration.
-
-
Run the OCR process with the
RunOCRmethod of theGdPictureOCRobject. -
Get the number of key-value pairs detected during the OCR process with the
GetKeyValuePairCountmethod of theGdPictureOCRobject, and loop through them. -
Get the key-value pairs, the data types, and the confidence scores with the following methods:
-
Write the output to the console.
-
Release unnecessary resources.
The example below retrieves key-value pairs from the following invoice.
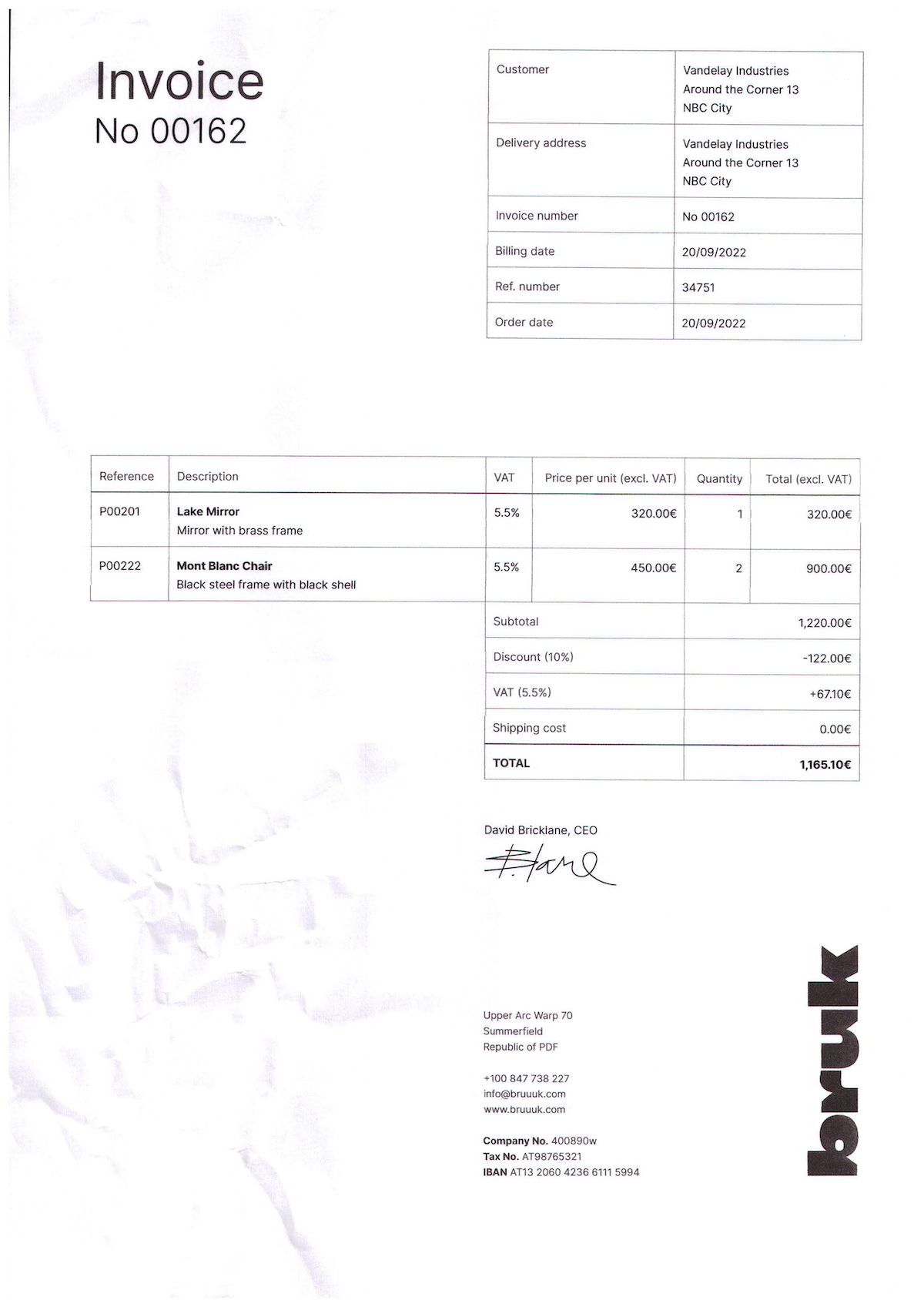
Download the sample invoice and run the code below, or check out our demo.
using GdPictureOCR gdpictureOCR = new GdPictureOCR(); using GdPictureImaging gdpictureImaging = new GdPictureImaging(); // Load the source document. int imageId = gdpictureImaging.CreateGdPictureImageFromFile(@"C:\temp\source.png"); // Configure the OCR process. gdpictureOCR.ResourceFolder = @"C:\GdPicture.NET 14\Redist\OCR"; gdpictureOCR.AddLanguage(OCRLanguage.English); gdpictureOCR.SetImage(imageId); // Run the OCR process. string ocrResultId = gdpictureOCR.RunOCR(); string keyValuePairsData = ""; for (int pairIndex = 0; pairIndex < gdpictureOCR.GetKeyValuePairCount(ocrResultId); pairIndex++) { keyValuePairsData += $"| Key: {gdpictureOCR.GetKeyValuePairKeyString(ocrResultId, pairIndex)} | " + $"Value: {gdpictureOCR.GetKeyValuePairValueString(ocrResultId, pairIndex)} | " + $"Document Type: {gdpictureOCR.GetKeyValuePairDataType(ocrResultId, pairIndex).ToString()} | " + $"Confidence Level: {Math.Round(gdpictureOCR.GetKeyValuePairConfidence(ocrResultId, pairIndex), 1).ToString()}% |\n"; } // Write the output to the console. Console.WriteLine(keyValuePairsData); // Release unnecessary resources. gdpictureImaging.ReleaseGdPictureImage(imageId); gdpictureOCR.ReleaseOCRResults();
Using gdpictureOCR As GdPictureOCR = New GdPictureOCR() Using gdpictureImaging As GdPictureImaging = New GdPictureImaging() ' Load the source document. Dim imageId As Integer = gdpictureImaging.CreateGdPictureImageFromFile("C:\temp\source.png") ' Configure the OCR process. gdpictureOCR.ResourceFolder = "C:\GdPicture.NET 14\Redist\OCR" gdpictureOCR.AddLanguage(OCRLanguage.English) gdpictureOCR.SetImage(imageId) ' Run the OCR process. Dim ocrResultId As String = gdpictureOCR.RunOCR() Dim keyValuePairsData = "" For pairIndex As Integer = 0 To gdpictureOCR.GetKeyValuePairCount(ocrResultId) - 1 keyValuePairsData += $"| Key: {gdpictureOCR.GetKeyValuePairKeyString(ocrResultId, pairIndex)} | Value: {gdpictureOCR.GetKeyValuePairValueString(ocrResultId, pairIndex)} | Document Type: {gdpictureOCR.GetKeyValuePairDataType(ocrResultId, pairIndex).ToString()} | Confidence Level: {Math.Round(gdpictureOCR.GetKeyValuePairConfidence(CStr(ocrResultId), CInt(pairIndex)), CInt(1)).ToString()}% |" & vbLf Next ' Write the output to the console. Console.WriteLine(keyValuePairsData) ' Release unnecessary resources. gdpictureImaging.ReleaseGdPictureImage(imageId) gdpictureOCR.ReleaseOCRResults() End Using End Using
Used Methods and Properties
Related Topics
Format the output to obtain the following table:
| Key | Value | Document Type | Confidence Level |
|---|---|---|---|
| Billing date | 20/09/2022 | DateTime | 100% |
| Order date | 20/09/2022 | DateTime | 100% |
| Republic of PDF | +100 847 738 227 | PhoneNumber | 77.2% |
| IBAN | AT13 2060 4236 6111 5994 | IBAN | 100% |
| Customer | Vandelay Industries Around the Corner 13 NBC City | String | 69.8% |
| Delivery address | Vandelay Industries Around the Corner 13 NBC City | String | 69.9% |
| Invoice number | No 00162 | String | 70.9% |
| Ref. number | 34751 | Number | 92.9% |
| No | 00162 | Number | 100% |
| Reference | P00201 | UID | 100% |
| Quantity Total (excl. VAT) | 320.00€ | Currency | 59% |
| Subtotal | 1,220.00€ | Currency | 100% |
| Discount (10%) | -122.00€ | Currency | 90.6% |
| VAT (5.5%) | +6710€ | Currency | 66.9% |
| Shipping cost | 0.00€ | Currency | 75% |
| TOTAL | 1,165.10€ | Currency | 100% |
| Description | Lake Mirror | String | 99.6% |
| VAT | 5.5% | Percentage | 66.6% |
| Price per unit (excl. VAT) | 320.00€ | Currency | 80% |
| Tax No. | AT98765321 | UID | 73.8% |
| # | info@bruuuk.com |
EmailAddress | 65.6% |
| # | www.bruuuk.com |
URL | 65.6% |
When the engine doesn’t recognize the data type of a value, it categorizes the value as a string, as shown in the table above.
This table also contains information about the data type and the confidence level for each key-value pair:
-
The data type describes the nature of the content. In this example, the engine recognizes the value
info@bruuuk.comas an email address and the value+100 847 738 227as a phone number. -
The confidence level describes how confident the KVP engine is in the accuracy of the data extraction.
In this example, the KVP engine automatically detected all key-value pairs in the document with minimal code and without any preconfiguration. The engine supports more than 100 formats and languages, and it has no dependencies to external models, resources, and databases.
How to Extract Data from Bank Statements
To extract data items from a bank statement, follow these steps:
-
Create a
GdPictureOCRobject and aGdPictureImagingobject. -
Select the bank statement by passing its path to the
CreateGdPictureImageFromFilemethod of theGdPictureImagingobject. -
Configure the OCR process with the
GdPictureOCRobject in the following way:-
Set the bank statement with the
SetImagemethod. -
Set the path to the OCR resource folder with the
ResourceFolderproperty. The default language resources are located inGdPicture.NET 14\Redist\OCR. For more information on adding language resources, see the language support guide. -
With the
AddLanguagemethod, add the language resources that GdPicture.NET uses to recognize text in the image. This method takes a member of theOCRLanguageenumeration.
-
-
Run the OCR process with the
RunOCRmethod of theGdPictureOCRobject. -
Get the number of key-value pairs detected during the OCR process with the
GetKeyValuePairCountmethod of theGdPictureOCRobject, and loop through them. -
Get the key-value pairs, the data types, and the confidence scores with the following methods:
-
Write the output to the console.
-
Release unnecessary resources.
The example below retrieves key-value pairs from the following bank statement.

Download the sample bank statement and run the code below, or check out our demo.
using GdPictureOCR gdpictureOCR = new GdPictureOCR(); using GdPictureImaging gdpictureImaging = new GdPictureImaging(); // Load the source document. int imageId = gdpictureImaging.CreateGdPictureImageFromFile(@"C:\temp\source.png"); // Configure the OCR process. gdpictureOCR.ResourceFolder = @"C:\GdPicture.NET 14\Redist\OCR"; gdpictureOCR.AddLanguage(OCRLanguage.English); gdpictureOCR.SetImage(imageId); // Run the OCR process. string ocrResultId = gdpictureOCR.RunOCR(); string keyValuePairsData = ""; for (int pairIndex = 0; pairIndex < gdpictureOCR.GetKeyValuePairCount(ocrResultId); pairIndex++) { keyValuePairsData += $"| Key: {gdpictureOCR.GetKeyValuePairKeyString(ocrResultId, pairIndex)} | " + $"Value: {gdpictureOCR.GetKeyValuePairValueString(ocrResultId, pairIndex)} | " + $"Document Type: {gdpictureOCR.GetKeyValuePairDataType(ocrResultId, pairIndex).ToString()} | " + $"Confidence Level: {Math.Round(gdpictureOCR.GetKeyValuePairConfidence(ocrResultId, pairIndex), 1).ToString()}% |\n"; } // Write the output to the console. Console.WriteLine(keyValuePairsData); // Release unnecessary resources. gdpictureImaging.ReleaseGdPictureImage(imageId); gdpictureOCR.ReleaseOCRResults();
Using gdpictureOCR As GdPictureOCR = New GdPictureOCR() Using gdpictureImaging As GdPictureImaging = New GdPictureImaging() ' Load the source document. Dim imageId As Integer = gdpictureImaging.CreateGdPictureImageFromFile("C:\temp\source.png") ' Configure the OCR process. gdpictureOCR.ResourceFolder = "C:\GdPicture.NET 14\Redist\OCR" gdpictureOCR.AddLanguage(OCRLanguage.English) gdpictureOCR.SetImage(imageId) ' Run the OCR process. Dim ocrResultId As String = gdpictureOCR.RunOCR() Dim keyValuePairsData = "" For pairIndex As Integer = 0 To gdpictureOCR.GetKeyValuePairCount(ocrResultId) - 1 keyValuePairsData += $"| Key: {gdpictureOCR.GetKeyValuePairKeyString(ocrResultId, pairIndex)} | Value: {gdpictureOCR.GetKeyValuePairValueString(ocrResultId, pairIndex)} | Document Type: {gdpictureOCR.GetKeyValuePairDataType(ocrResultId, pairIndex).ToString()} | Confidence Level: {Math.Round(gdpictureOCR.GetKeyValuePairConfidence(CStr(ocrResultId), CInt(pairIndex)), CInt(1)).ToString()}% |" & vbLf Next ' Write the output to the console. Console.WriteLine(keyValuePairsData) ' Release unnecessary resources. gdpictureImaging.ReleaseGdPictureImage(imageId) gdpictureOCR.ReleaseOCRResults() End Using End Using
Used Methods and Properties
Related Topics
Format the output to obtain the following table:
| Key | Value | Document Type | Confidence Level |
|---|---|---|---|
| IBAN | FR7611808009101234567890147 | IBAN | 100% |
| Phone | 786-315-0313 | PhoneNumber | 100% |
| BIC | 12345678901 | Number | 66.4% |
| Bank Code | 11808 | Number | 99.4% |
| Counter Code | 00914 | Number | 100% |
| Number Account | 12345678901 | Number | 99.3% |
| Bank Key | 47 | Number | 74.2% |
| River Bank | 100 | Number | 74% |
| Account Owner | David Bricklane | String | 100% |
| Domiciliation | East Bank Summerfield | String | 97.5% |
Conclusion
You should now have a basic understanding of how GdPicture.NET’s key-value pair (KVP) extraction engine works, and how it ensures accurate and reliable extraction results. If you have any questions or want to discuss how to implement it in your workflows and projects, you can reach out to our team.




{kind=link}
{kind=link}